1.字符编码简介
字符编码从字面上理解,就是将字符编码为由多个bits(0或1)组成的字节序列。但字符和字节序列的映射并不是直接的,可简要概括为2个步骤,第1步由字符映射到unicode码,第2步由unicode码映射到字节码[1]。工作中ASCII,ISO8859-1,GBK,UTF-8这几种编码方式使用的比较多,它们的字符编码的步骤如表1。步骤1中映射到的unicode码是统一的,即一个字符唯一映射到一个unicode码,与编码方式无关;unicode码包含2-3个字节,unicode的取值范围由0至0x10FFFFFF(共21个bit)[2],通常可用1-3个字节表示,高位补零至2-3个字节即为实际的Unicode编码。jvm中的String在内存中以Unicode码存储,这样的设计相比于存储字节码更简单,如果存储字节码,那String类型还需要有个encodingType(编码方式)的属性,这是统一的Unicode编码的使用场景之一。可否不经过Unicode码的过渡,直接将每个字符映射到统一的字节码呢?答案是不行,因为在Unicode码出来以前,世界上已经有很多种编码方式,欧洲的ISO8859系列(共14种)编码、大陆的GB2312、台湾的Big5,日本的JIS X 0212和韩国的Johab等[3],每种编码方式的映射规则都有差异,如果直接将字符映射到统一的字节码,肯定是无法兼容之前的编码方式的。GBK18030是可以兼容Unicode统一前的GBK2312的,这也是GBK18030的字节编码和Unicode码的映射没有简单的规则的原因[4]。相比之下,UTF-8是基于Unicode的全新的编码方式,它和Unicode的映射规则相对简单。比如U+0080至U+07FF的Unicode码会映射到2个字节的UTF-8编码。如图1,Unicode码的后6位bit,加上0x80,就是第二个字节;紧接着的5位bit,加上0xC0,就是第一个字节。其它范围内的Unicode编码与UTF-8编码也有简单的映射关系。[4]
表1中的ASCII和ISO8859-1是单字节编码,最多可表示256个字符。ASCII编码的字符集[5]如图2所示,包括英文字母、数字、标点符号和控制字符(比如DEL等),不同的编码方式中ASCII字符集的编码一般是统一的。ISO8859-1编码的字符集如图3所示,它在ASCII字符集的基础上新增了拉丁字符;它是浏览器早期处理请求头和应答头的默认编码方式,后来更改为由ISO8859-1(包含191个字符)扩展的Windows-1252(包含251个字符)[6]。UTF-8和GBK是2种常用的多字节编码方式,UTF-8的字节码由1-4个字节组成,GBK18030的字节码由1、2或4个字节组成[7]。同一个中文字符使用UTF-8和GBK编码后的字节码通常是不同的。UTF-8和GBK是2种常用的中文编码方式,如果实际开发中处理不当,可能会出现乱码。比如表1的UTF-8字节编码使用GBK解码后的字符是"灞"(GBK编码为E5 B1),GBK的字节码使用UTF-8解码后的字符是"ɽ"(UTF-8编码为C9 BD),它们解码出的字符与原有字符"山"明显不同,第二个解码出的字符"ɽ"不是常见字符,可以理解为出现了乱码。
编码方式字符Unicode码字节码(1个字节由2个16进制的数字表示)ASCIIa%6161ISO8859-1å%E5E5UTF-8山\u5C71E5 B1 B1GBK山\u5C71C9 BD表1 不同编码方式的编码步骤,从字符映射到Unicode码,在由Unicode码映射到字节码
图1 U+0080至U+07FF的Unicode码会映射到2个字节的UTF-8编码
图2 ASCII编码的字符集[5]
图3 Windows-1252编码的字符集[8]
2.java程序中字符从输入到输出的流程
2.1 一个简单案例
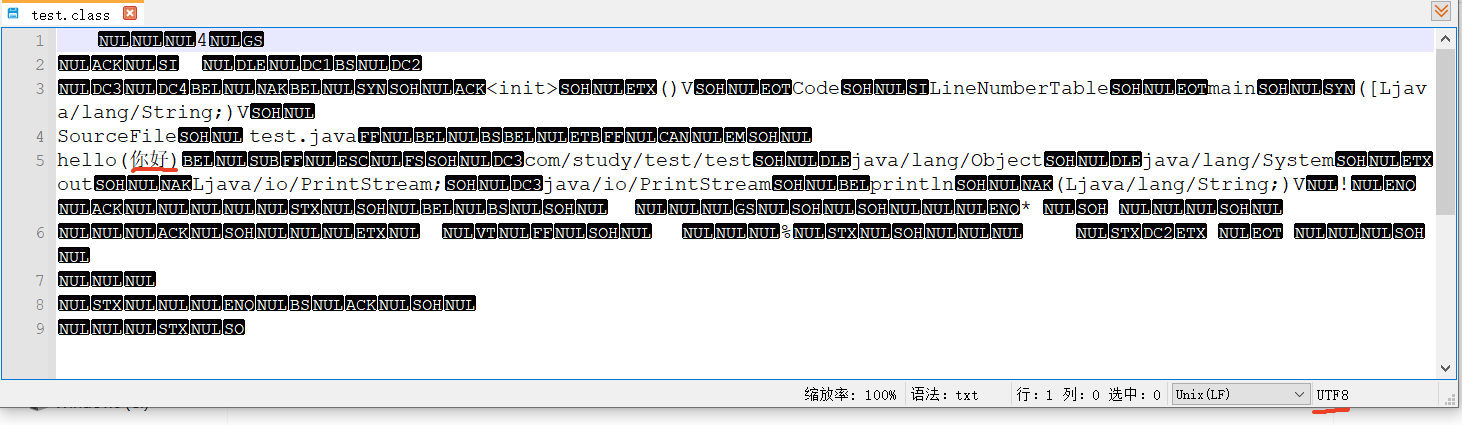
如Demo1所示的test.java,在cmd窗口中使用javac命令编译为test.class文件,然后使用java命令运行test.class文件时,在控制台会输出"hello(你好)!"。实际运行时可能会出现中文乱码,如表2所示,运行时在控制台输出的字符是否乱码受4个因素影响。如表2的记录1,test.java中存储的是UTF-8编码后的字节,在cmd窗口使用命令javac -encoding UTF-8 test.java指定编译test.java时的编码方式为UTF-8,编译后生成test.class文件;然后使用java -Dfile.encoding=UTF-8 test指定运行test.class时的编码方式为UTF-8,cmd窗口的编码为UTF-8,运行后在cmd窗口输出hello(你好)!。cmd窗口的默认编码方式与操作系统的编码方式一致,可以通过chcp查看字符编码,可以通过chcp 编码方式编号 切换编码方式,chcp 65001切换到UTF-8,chcp 936切换到GBK。表2中当4个影响因素的编码方式变化时,cmd窗口的输出有时正常,有时会乱码。4个因素对运行结果的影响可以分为2个阶段,第1阶段将test.java编译为test.class文件;第2阶段运行test.class文件,在cmd窗口输出字符。如表2记录1,文件test.java中的中文字符”你好“以UTF-8字节”E4 BD A0 E5 A5 BD“存储,javac命令使用UTF-8将test.java中UTF-8字节解码为字符”你好“(字符串“你好”在内存中以Unicode码”\u4f60\u597d“存储),并生成test.class文件,test.class文件中字符以UTF-8字节”E4 BD A0 E5 A5 BD“存储。test.class文件中的字符以UTF-8字节存储是由jvm决定的,不受其它因素影响。生成的test.class文件如图4所示,使用nodepad--打开时会默认使用UTF-8编码。java命令使用UTF-8将test.class文件中的UTF-8字节解码为字符”你好“,这里的UTF-8是由jvm决定的;然后将字符以UTF-8编码后的字节”E4 BD A0 E5 A5 BD“输出到cmd窗口。cmd窗口使用UTF-8解码UTF-8编码后的字节,并在cmd窗口中展示中文字符”你好“。如表2记录5,文件test.java中的中文字符”你好“以UTF-8字节”E4 BD A0 E5 A5 BD“存储,javac命令使用GBK将test.java中UTF-8字节解码为字符”浣犲ソ“,并生成test.class文件,test.class文件中字符”浣犲ソ“以UTF-8字节”E6 B5 A3 E7 8A B2 E3 82 BD“存储,生成的test.class文件如图5所示。java命令使用UTF-8(由jvm决定,不受其它因素影响)将test.class文件中的UTF-8字节解码为字符”浣犲ソ“,然后将字符以GBK编码(java命令运行时指定的编码)后的字节”E4 BD A0 E5 A5 BD“输出到cmd窗口。cmd窗口使用UTF-8解码GBK编码后的字节,并在cmd窗口中展示”你好“。记录5虽然在test.java编码运行的过程中中文字符”你好“出现了乱码,但是最终cmd窗口的展示没有乱码,这是由于共经过2次UTF-8编码、1次GBK编码、2次UTF-8解码和1次GBK解码后,运行过程中的乱码被还原了。记录6相对于记录5前3个因素是相同的,但cmd窗口编码变为GBK,最终cmd窗口中文字符”你好“的展示出现了乱码,最终展示为”浣犲ソ“。
Demo1中cmd窗口的展示是否乱码受4个因素影响,4个因素可以分为2个阶段。第1阶段生成test.class文件,第2阶段运行test.class文件。test.class文件的字节编码为UTF-8,这是由jvm决定的,jvm运行时读取test.class文件时,也使用UTF-8解码。4个因素变化时,执行结果如表2所示。如表2记录1,前3个因素的编码都为UTF-8,cmd窗口的编码为UTF-8或GBK时,执行结果都是正常的;而记录5和6中前3个因素的编码是相同的,只是cmd窗口编码一个是GBK,一个是UTF-8,但执行结果却不同。笔者猜测是由于System.out.println()的底层实现引起的,当java命令的编码为UTF-8时,System.out.println()输出的编码会随着cmd窗口编码的变化而变化;而当java命令的编码为GBK时,System.out.println()输出字节为GBK编码的,不会随cmd窗口的变化而变化。之所以这么猜测是因为UTF-8是比较特殊的,比如浏览器对URL的处理就是将URL转换UTF-8编码后字节的字符串(详见2.2.1.1节),javac命令编译生成.class文件是以UTF-8编码后的字节存储的。但是由于System.out.println()的底层实现比较复杂[9],笔者未深入学习,所以这里只是猜测,并没有验证。- //package com.study.test;
- //import com.sun.tracing.dtrace.ModuleAttributes;
- public class test {
- public static void main(String[] args) {
- System.out.println("hello(你好)!");
- }
- }
序号文件编码javac -encodingjava -Dfile.encodingcmd窗口编码执行后cmd窗口展示1utf-8utf-8utf-8utf-8/gbkhello(你好)!2utf-8utf-8gbkutf-8hello()!3utf-8utf-8gbkgbkhello(你好)!4utf-8gbkutf-8utf-8/gbkhello(浣犲ソ)!5utf-8gbkgbkutf-8hello(你好)!6utf-8gbkgbkgbkhello(浣犲ソ)!7gbkgbkgbkgbkhello(你好)!8gbkgbkgbkutf-8hello()!9gbkgbkutf-8utf-8/gbkhello(你好)!10gbkutf-8gbkgbkjavac报错11gbkutf-8gbkutf-8javac报错12gbkutf-8utf-8utf-8/gbkjavac报错表2 Demo1中的程序运行时在cmd窗口输出的字符是否乱码受4个因素影响
图4 UTF-8编码的test.java文件使用UTF-8编码编译后test.class
图5 UTF-8编码的test.java文件使用GBK编码编译后test.class
2.2 java程序中的字符输入和输出
2.2.1 前后端交互
2.2.1.1 前后端交互时的请求和应答
Ajax是前后端交互的一种常用方式。如Demo2,前端向后端发送一个ajax请求。服务端接收到请求后,进行逻辑处理后,返回应答到前端,如Demo3。开发环境是Tomcat6+jdk6,Tomcat7以前的默认编码是ISO8859-1[10]。在实际开发时,如果编码方式处理不当,可能会出现乱码问题。在笔者经历的3个金融老项目(开发环境是Tomcat6+jdk6)中,前后端交互时都出现过乱码的问题。Tomcat7以前的默认编码方式是ISO8859-1,ISO8859-1是包含拉丁字符集的单字节编码方式(最多256个编码点),这主要考虑到早期以欧洲开发者为主的情形。浏览器请求头和应答头的编码方式至今仍是ISO8859-1[11]。- <%@ page language="java" contentType="text/html; charset=UTF-8"
- pageEncoding="UTF-8"%>
- <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
- <html>
- <head>
- <meta http-equiv="Content-Type" content="text/html; charset=GBK">
- <title>Insert title here</title>
- </head>
- <body>
- <h1>使用ajax测试编码方式</h1>
- <input type="button" value="发送Ajax请求" onclick="sendAjax()"/><br/>
- </body>
- </html>
- public class HelloServlet extends HttpServlet {
- protected void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- //1.请求头url中请求参数获取
- //方式1:request.setCharacterEncoding("gbk");
- String name = request.getParameter("name");
- //方式2:
- name = new String(name.getBytes("iso8859-1"),"utf-8");
- System.out.println(name);
- //2.返回应答体
- response.setContentType("text/html;charset=utf-8");
- response.getWriter().print("hello,"+name);
- }
- }
在发送ajax请求之前,会进行hello.jsp的页面初始化。页面初始化是指浏览器发起请求后,服务端应答html页面的过程;浏览器实际请求的是hello.jsp编译后生成的hello_jsp.class中的servlet(如Demo4),hello_jsp.class所在目录可以在启动日志中看到(如图6)[12]。hello.jsp初始化的编码通过page指令中content-type进行配置(如Demo2),在编译生成的hello_jsp.java中该content-type转化为 response.setContentType(如Demo4)。该content-type决定浏览器打开应答的html页面时的编码方式。如Demo2的page指令中还配置了pageEncoding,它表示jvm将hello.jsp编译为hello_jsp.class使用的编码(相当于2.1节javac命令的编码);在IntelliJ IDEA工具中,当修改page-encoding时,jsp的文件编码会跟着变化。如果contentType或page-ecoding只配置了1个,另一个属性值会默认为已配置的属性值。如果contentType和pageEncoding均未配置,contentType和pageEncoding的默认编码是ISO8859-1[13]。- public final class hello_jsp extends org.apache.jasper.runtime.HttpJspBase
- implements org.apache.jasper.runtime.JspSourceDependent {
- public void _jspService(HttpServletRequest request, HttpServletResponse response)
- throws java.io.IOException, ServletException {
- try {
- response.setContentType("text/html; charset=UTF-8");
- pageContext = _jspxFactory.getPageContext(this, request, response,
- null, true, 8192, true);
- out = pageContext.getOut();
- out.write("\r\n");
- out.write("\r\n");
- out.write("<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">\r\n");
- out.write("<html>\r\n");
- out.write("<head>\r\n");
- out.write("<meta http-equiv="Content-Type" content="text/html; charset=GBK">\r\n");
- out.write("<title>Insert title here</title>\r\n");
- out.write("\r\n");
- out.write("</head>\r\n");
- out.write("<body>\r\n");
- out.write("\t<h1>使用ajax测试编码方式</h1>\r\n");
- out.write("\t<input type="button" value="发送Ajax请求" onclick="sendAjax()"/><br/>\r\n");
- out.write("</body>\r\n");
- out.write("</html>");
- } catch (Throwable t) {
- } finally {
- }
- }
- }

图6 编译生成的hello_jsp.java所在目录
浏览器发送ajax请求时,会对URL进行encodeURIComponent的处理,如图7步骤2。encodeURIComponent对原始URL字符串进行一系列处理得到新的URL字符串。步骤1中原始URL字符串为http://localhost:8082/test/hello?name=jack(杰克),经过步骤2中encodeURIComponent处理后的字符串为/test/hello?name=jack(%E6%9D%B0%E5%85%8B)(如图8),其中原来的value值“杰克”被替换为UTF-8编码后字节并在字节前面拼接“%”[14]。步骤3中使用URLDecoder.decode对URL字符串对URL字符串进行还原,但还原后的URL字符串是乱码的;这是因为Tomcat6的默认编码是ISO8859-1[10],默认使用iso8859-1处理URL、请求头和应答头,开发者在开发时需要使用UTF-8重新解码(步骤4),这样才能输出正常的字符串。步骤4对应demo3中的name = new String(name.getBytes("iso8859-1"),"utf-8"),可见String中存储的并不是字节码,String中存储的是Unicode码。如果步骤4中不使用UTF-8重新解码,直接返回字符æ°å
使用UTF-8编码的字节,那么步骤5中将展示乱码字符串æ°å
。步骤5对应demo1中的console.log(xmlhttp.responseText),步骤5中的编码方式是由页面的content-type决定。可以通过demo1中的方式配置content-type,也可以通过demo2中的response.setContentType("text/html;charset=utf-8")的方式配置content-type,后者仅对当前应答有效,后者的优先级更高。

图7 前后端交互字符编解码的流程

图8 经过encodeURIComponent处理后的URL字符串
2.2.1.2 请求头
Demo5实现了在请求头中携带中文字符,请求头在前后台处理的详细流程如图9。如图9步骤1-2,浏览器发送ajax请求时,携带请求头authorization,authorization的值是使用encodeURIComponent()处理后的,其中中文字符串“令牌”被转换为UTF-8编码后字节并在字节前面拼接“%”[14],转换后authorization的值为aaaaa.bbbbb.ccccc(%E4%BB%A4%E7%89%8C)。步骤3中浏览器使用ISO8859-1编码字符,步骤4中Tomcat使用ISO8859-1解码字符,解码出的中文字符串还是%E4%BB%A4%E7%89%8C。如果没有步骤2,步骤3中使用ISO8859-1编码中文字符串“令牌”会报出如图10的错误,因为ISO8859-1不支持中文字符。步骤5中使用URLDecoder.decode()将字符串%E4%BB%A4%E7%89%8C还原为“令牌”,对应的后台代码如Demo6。
图9 请求头中携带中文的处理流程
图10 请求头中包含中文字符时,如果不使用encodeURIComponent()处理会报错- [/code]Demo5 hello.jsp文件中请求头携带中文字符
- [code]protected void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- //3.请求头authorization获取
- String authorization = request.getHeader("authorization");
- authorization = URLDecoder.decode(authorization,"UTF-8");
- System.out.println(authorization);
- }
2.2.1.3 应答头
Demo7实现了文件下载,文件名通过应答头Content-Disposition返回给浏览器。文件下载时的流程如图11所示。如图11步骤1-3,在浏览器发送文件下载请求,浏览器对URL进行encodeURIComponent()的处理,Tomcat对URL进行URLDecoder.decode()的处理。因为.java文件的编码方式和编译.java文件的方式都是UTF-8,所以步骤4中字符为“卷一”。由于tomcat6在返回应答头时会对字符(Unicode码)使用ISO8859-1重新编码(如步骤6),所以开发者需要进行步骤5的处理,将UTF-8字节码使用ISO8859-1先解码一下,再经过步骤6处理后,返回应答中的字节码还是UTF-8字节码。如果没有步骤5,直接对字符“卷一”进行步骤6的操作,由于ISO8859-1不支持中文字符,步骤6处理后tomcat无法正常返回,如图12。在没有步骤5时,步骤6中tomcat会对某些中文字符(比如“说”、“明”、“文”、“件”、“下”和“载”等)特殊处理。将Demo7中的文件名改为“说明”,重新发起下载请求,由于没有如图11步骤5的操作,应该无法正常返回,但实际测试时可成功返回,下载后文件的文件名为“�_ ”。tomcat对“说”和“明”等字符的特殊处理,笔者并没有找到相关资料。
图11 文件下载时应答头处理流程- public class HelloServlet extends HttpServlet {
- protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
- //3.文件下载,返回应答头Content-Disposition
- response.setContentType("text/plain;charset=GBK");
- String fileName = "卷一.txt";
- fileName = new String(fileName.getBytes("utf-8"),"iso8859-1");
- response.setHeader("Content-Disposition", "attachment;filename="+ fileName);
- InputStream in = new FileInputStream("D:\\卷一.txt");
- int len=0;
- byte buffer[]= new byte[1024];
- OutputStream out = response.getOutputStream();
- while((len=in.read(buffer))>0){
- out.write(buffer,0,len);
- }
- }
- }
图12 当图1中缺少步骤5时,下载请求无法正常返回
在前后端交互的流程中,在UTF-8和ISO8859-1编码方式间进行了多次转换。图11的步骤5中,使用ISO8859-1解码UTF-8编码的字节。ISO8859-1是单字节编码,但有几个代码点是空的(没有对应的字符),可能会导致无法正常解码(解析为Unicode码),实际测试是可以正常解码的,并没有出现类似4.3节所描述的gbk解码utf-8字节时出现乱码的情况。因为java中字符串的处理是基于Unicode码的,如果有些utf-8字节码无法正常使用iso8859-1解码为Unicode码,则会解析为默认的Unicode码�(\ufffd),该Unicode码在使用iso-8859-1编码后的字节码与初始的字节码不同,字节码先后经过iso8859-1解码和编码后并未还原,这会导致乱码。不过ISO8859-1的字节编码和Unicode编码是直接映射的关系,没有乱码的问题。
2.2.1.4 请求体和应答体
在发送post类型的Ajax请求或提交表单时,通常会携带请求体。post请求的发送方式有4种[7],本节只讨论以如Demo8的方式发送post请求。如Demo8,前端向后端发送post请求,在发送前设置了请求头content-type为application/x-www-form-urlencoded。这表示浏览器和Tomcat会以处理URL的方式来处理请求体。如图13步骤1,浏览器向服务端发送url为/hello的请求,请求体为name:jack(杰克)。浏览器会对请求体使用encodeURIComponent()进行处理,其中中文字符“杰克”被转换为UTF-8编码后字节并在字节前面拼接“%”[14],转换后的字符串为%E6%9D%B0%E5%85%8B。步骤3中使用URLDecoder.decode对请求体中的中文字符进行还原,但还原后的字符是乱码的;通常Tomcat默认编码ISO8859-1只针对URL、请求头和应答头,但因为在发送请求体时设置了请求头content-type为application/x-www-form-urlencoded,浏览器以处理URL的方式处理了请求体,Tomcat可能也会默认使用ISO8859-1处理该请求体。步骤4中开发者需要使用UTF-8重新将字节码解码为字符(如Demo9),解码后可在控制台正常输出。步骤4的代码实现有2种方式,一种是通过request.setCharacterEncoding("gbk"),另一种是通过new String(name.getBytes("iso8859-1"),"utf-8")。第一种方式并不适用于URL中参数的处理(见2.2.1.1节),原因是这种方式只适用于post类型的请求,对get类型的请求无效[10]。
图13 post类型的Ajax请求的请求体处理流程- function sendAjax() {
- var xmlhttp=new XMLHttpRequest();
- xmlhttp.onreadystatechange = function(){
- if(xmlhttp.readyState == 4 && xmlhttp.status == 200){
- console.log(xmlhttp.responseText)
- }
- }
-
- xmlhttp.open("post","${pageContext.request.contextPath}/hello");
- xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlencoded");
- xmlhttp.send("name=jack(杰克)");
- }
- protected void doPost(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- //方式1:request.setCharacterEncoding("gbk");
- String name = request.getParameter("name");
- //方式2:
- name = new String(name.getBytes("iso8859-1"),"utf-8");
- System.out.println(name);
- }
服务端在返回应答体时,Tomcat和浏览器不会默认使用编码方式ISO8859-1。返回的字节码编码的编码方式与浏览器解码的编码方式一致即可,返回字节码的编码方式默认是jvm运行的编码方式;浏览器解码的编码方式由content-type决定。具体案例详见2.2.1.1节。
虽然浏览器和Tomcat6默认使用ISO8859-1处理URL、请求头和应答头,并且当发送请求体时设置了请求头content-type为application/x-www-form-urlencoded浏览器和Tomcat6也会默认使用ISO8859-1处理,浏览器和Tomcat6的底层处理在实际开发时并不容易感受到。对于URL、应答头和请求体,如果Tomcat的默认编码方式(如图14)设置为与jvm运行的编码方式一致,并不需要在ISO8859-1和jvm运行时的编码方式之间进行转换。对于请求头,请求头的值不能是中文字符,在请求头中携带中文时需要使用encodeURIComponent()对中文字符串进行处理(详见2.2.1.2节),但这种场景在实际开发中一般不会碰到。对于应答体,Tomcat的默认编码对其没有影响。
图14 配置tomcat6的编码方式为utf-8
2.2.2 其它类型的字符输入和输出
除了前后端交互外,字符的输入输出还包括文件读写,数据库读写等。文件读写和数据库读写的字符编解码相对简单,保证读写的编码一致即可,并没有像前后端交互时,浏览器默认用encodeURIComponent()处理URL,用ISO8859-1处理请求头和应答头,tomcat6默认使用ISO8859-1处理请求头和应答头等特殊的情况。所以文件读写和数据库读写在这里不展开叙述了,只是将实际开发中碰到的问题记录在第4节中。
3.在服务器和IDE工具中编码方式的配置
3.1 Tomcat
Tomcat常用的字符编码配置有2处。一处是前后端交互使用的编码方式(详见2.2.1.3节),另一处是Tomcat运行时使用的jvm编码。Tomcat在window系统默认的jvm编码是GBK,在Linux系统默认的jvm编码是UTF-8[15]。如Demo11,在windows系统中,可以通过在catalina.bat中配置set JAVA_OPTS=%JAVA_OPTS% -Dfile.encoding=UTF-8指定运行时的编码。变量JAVA_OPTS在运行如Demo10的脚本startup.bat时使用,startup.bat中调用如Demo11的catalina.bat,catalina.bat中执行%_EXECJAVA% %JAVA_OPTS%,其中变量%_EXECJAVA%的取值%_RUNJAVA%是在如Demo12的setclasspath.bat中定义,catalina.bat实际执行的命令包含%JRE_HOME%\bin\java -Dfile.encoding=UTF-8,可以看出在catalina.bat中该配置是运行java命令的编码方式。- set "EXECUTABLE=%CATALINA_HOME%\bin\catalina.bat"
- call "%EXECUTABLE%" start %CMD_LINE_ARGS%
- set _EXECJAVA=%_RUNJAVA%
- rem 指定运行java程序的编码方式
- set JAVA_OPTS=%JAVA_OPTS% -Dfile.encoding=UTF-8
- %_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
- set _RUNJAVA="%JRE_HOME%\bin\java"
3.2 IntelliJ IDEA
在IDEA中使用tomcat运行java程序时,需要注意4个位置的编码方式[16],它们分别与2.1节中影响test.java运行结果的4个因素相对应。笔者测试时使用的IDEA版本是”IntelliJ IDEA 2019.2.3“。
- java文件的编码方式。在IDEA中配置该编码方式的菜单是File > Settings > Editors > File Encodings(如图15)。该编码方式对应2.1节中test.java文件的编码方式。
图15 菜单File > Settings > Editors > File Encodings中的编码方式配置
- java文件编译时的编码方式。windows环境下cmd窗口中运行javac命令时默认编码方式为GBK,但在IDEA工具中测试时java文件编译使用的编码方式是UTF-8。笔者未找到修改这个编码的方式,这个编码对应2.1节javac命令运行的编码方式。
- tomcat中java程序运行的编码方式。如3.1节,window环境下java程序运行的默认编码方式为GBK,在IDEA工具中测试时tomcat中java程序运行的默认编码也是GBK。可以通过在IDEA工具中的配置VMOptions中添加 -Dfile.encoding=UTF-8来修改该编码方式(如图16)。
图16 在 VMOptions 配置中添加 -Dfile.encoding=UTF-8
- 控制台展示日志的编码方式。cmd窗口展示日志的默认编码方式与操作系统的编码方式一致。在IDEA工具中测试时该编码方式默认为GBK,测试时win10系统的编码为UTF-8。笔者测试时发现,控制台的编码方式与菜单Help > Edit CustomVMOptions下的配置有关,如图17在文件末尾添加”-Dfile.encoding=UTF-8“,保存并重启IDEA工具后,控制台的编码会切换为UTF-8。
图17 菜单Help > Edit CustomVMOptions下添加 -Dfile.encoding=UTF-8
4.实际开发中的问题
4.1 控制台输出乱码
如图18,在tomcat中启动java项目时控制台日志出现乱码。出现乱码的是tomcat服务器输出的日志。tomcat启动时,会加载tomcat官方jar包中的class文件,然后运行class文件,运行时向控制台输出日志。jar中的class文件中的中文正常情况下是没有乱码的(使用UTF-8解码没有乱码,参考2.1节),应该是java程序运行时的编码和控制台展示的编码出现了问题。检查相应的配置(参考3.2节)发现VMOptions中已配置”-Dfile.encoding=UTF-8“;但Help > Edit CustomVMOptions中并未进行配置,它决定控制台的编码方式。java程序运行时向控制台输出字符”信息“用UTF-8编码后的字节”E4 BF A1 E6 81 AF“,控制台使用GBK将该字节解码为”淇℃伅“(如图18),出现了乱码。通过在Help > Edit CustomVMOptions菜单下的文件末尾添加”-Dfile.encoding=UTF-8“,即可解决该问题。
图18 tomcat启动时控制台日志出现乱码
4.2 前后端交互乱码
前后端交互时出现乱码主要是在一些使用tomcat6的老项目中。在笔者经历的3个金融老项目(开发环境是Tomcat6+jdk6)中,前后端交互时都出现过乱码的问题。常见的问题有2种,一种是获取GET请求URL中的请求参数乱码;另一种是下载文件的文件名乱码。如Demo13,当浏览器发送请求/hello?name=jack(杰克)时,直接通过request.getParameter("name")获取的请求参数name的值为"jack(æ°å
)",获取后需要使用new String(name.getBytes("iso8859-1"),"utf-8")处理一下即可解决乱码问题(详见2.2.1.1节)。如Demo14,当浏览器发送请求/hello时,会进行文件下载,下载后的文件名为“�_ ”,这是由于后台设置的文件名没有做编码方式的转换,在设置文件名前使用new String(fileName.getBytes("utf-8"),"iso8859-1")进行转码即可解决该问题(详见2.2.1.3节)。- public class HelloServlet extends HttpServlet {
- protected void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- //1.请求头url中请求参数获取
- String name = request.getParameter("name");
- //name = new String(name.getBytes("iso8859-1"),"utf-8");
- System.out.println(name);
- }
- }
- public class HelloServlet extends HttpServlet {
- protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
- //3.文件下载,返回应答头Content-Disposition
- response.setContentType("text/plain;charset=GBK");
- String fileName = "说明.txt";
- //fileName = new String(fileName.getBytes("utf-8"),"iso8859-1");
- response.setHeader("Content-Disposition", "attachment;filename="+ fileName);
- InputStream in = new FileInputStream("D:\\说明.txt");
- int len=0;
- byte buffer[]= new byte[1024];
- OutputStream out = response.getOutputStream();
- while((len=in.read(buffer))>0){
- out.write(buffer,0,len);
- }
- }
- }
4.3 文件名乱码后无法正常复制
笔者在工作中开发了一个文件备份的功能。在文件备份时,有些源文件的文件名是乱码的,测试时发现有些文件名乱码的文件可以复制,有些文件名乱码的文件无法复制。Demo15是文件备份简化后的代码,代码在Linux环境运行。Linux系统的编码是GBK,Tomcat的运行编码也设置为GBK(详见3.1节)。使用SecureCRT8.7.0连接到Linux服务器,设置终端的编码方式为UTF-8,上传如图19的文件至src目录下;终端的编码方式切换为GBK,src目录下的文件名是乱码的(如图20)。运行Demo15的文件备份程序后,备份目标目录下的文件如图21所示,3个文件中有2个文件备份成功,1个文件备份失败,备份失败的文件是缁撶畻鍗曟枃浠?.txt。如Demo15,程序运行时遍历源目录下的文件,获取文件名的UTF-8字节码,使用GBK解码为字符(Unicode码),再根据字符使用GBK编码后的字节码获取文件输入流。源文件的文件名出现”?“,是因为无法使用GBK正常解码文件名中的UTF-8字节码B6,源文件名的字节码B6使用GBK解码后的字符(�)再使用GBK编码后的字节码(3F)将与源文件名的字节码(B6)不同。这使得备份程序运行后,源目录下文件名中包含?的文件不能被复制。- public class FileBakServlet extends HttpServlet {
- protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
- String src = "/data/file_copy_test/src";
- String dest = "/data/file_copy_test/dest";
- File file = new File(src);
- for(File child:file.listFiles()){
- FileInputStream in = null;
- FileOutputStream out = null;
- try {
- in = new FileInputStream(src+File.separator+child.getName());
- out = new FileOutputStream(dest+File.separator+child.getName());
- byte[] bytes = new byte[1024];
- int len = 0;
- while((len = in.read(bytes))!=-1){
- out.write(len);
- }
- } catch (IOException e) {
- try{
- if(in !=null){
- in.close();
- }
- if(out != null){
- out.close();
- }
- }catch (IOException e2){
- System.out.println("流关闭异常");
- e.printStackTrace();
- }
- e.printStackTrace();
- }
- }
- }
- }
图19 远程终端编码设置为UTF-8时,上传文件到src目录下
图20 终端编码设置为GBK时,src目录下的文件名出现乱码
图21 文件备份运行后,目标目录下文件
4.4 jdk6文件找不到时日志乱码
如Demo16的代码在jdk6环境下运行,当文件“D:\卷二.txt”不存在时,控制台输出的异常日志如图22。错误信息为D:\卷二.txt (绯荤粺鎵句笉鍒版寚瀹氱殑鏂囦欢銆�),其中前面部分的中文没有乱码,后面部分的中文出现乱码。前面部分D:\卷二.txt是test.java中的文件路径,因为相关的编码方式(详见2.1节)配置的都是UTF-8,因此该部分没有出现乱码。后面部分(绯荤粺鎵句笉鍒版寚瀹氱殑鏂囦欢銆�)是在调用构造方法FileInputStream()时抛出的异常信息,查看源码FileInputStream会调用本地方法open,所以猜测本地方法open中的异常信息已经是乱码的。由于可能是jdk6的本地方法open出了问题,笔者没找到解决乱码的方法。jdk8中没有类似的问题。- public class test {
- public static void main(String[] args) {
- try {
- InputStream in = new FileInputStream("D:\\卷二.txt");
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- }
- }
- }
图22 Demo1在jdk6环境下运行的报错
4.5 如何修改win10系统的编码
修改win10系统的编码有4种方式[17],笔者通过其中的方式1和方式4修改win10的编码为utf8。方式1的步骤为打开控制面板界面,点击“时钟和区域”设置;接着,继续点击“区域”。然后,在弹出的窗口中,切换到“管理”选项栏;随后,点击下方的“更改系统区域设置”选项。此时,勾选“使用Unicode UTF-8”,点击确定即可,如图23。方式2的步骤为在注册表编辑器中,导航到"HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage"路径下,修改"ACP"键的值为65001,如图24。
图23 修改win10系统编码的方式
图24 修改win10系统编码的方式
参考资料
[1] Gillam, Richard.Unicode demystified : a practical programmer's guide to the encoding standard[M].Addison-Wesley, 2003:30-31.
[2] Gillam, Richard.Unicode demystified : a practical programmer's guide to the encoding standard[M].Addison-Wesley, 2003:131.
[3] Gillam, Richard.Unicode demystified : a practical programmer's guide to the encoding standard[M].Addison-Wesley, 2003:28-36.
[4] https://www.cnblogs.com/jann8/p/16560099.html#532-gb18030
[5] https://en.wikipedia.org/wiki/ASCII
[6] https://en.wikipedia.org/wiki/ISO/IEC_8859-1
[7] https://www.cnblogs.com/jann8/p/17472129.html
[8] https://en.wikipedia.org/wiki/Windows-1252
[9] https://luckytoilet.wordpress.com/2010/05/21/how-system-out-println-really-works/
[10]https://www.cnblogs.com/panxuejun/p/6837677.html
[11] https://en.wikipedia.org/wiki/ISO/IEC_8859-1#cite_note-WHATWG-3
[12] https://blog.csdn.net/Acx77/article/details/122011579
[13] JavaServer Pages™ Specification Version2.1:44,90-91.
[14] https://htmlspecs.com/url/#concept-urlencoded-serializer
[15]https://www.cnblogs.com/wlv1314/p/12150477.html
[16] https://mbd.baidu.com/newspage/data/dtlandingsuper?nid=dt_4324937715964348777&sourceFrom=search_b
[17] https://www.jb51.net/os/win10/937427.html
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |






















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



