 羊夏菡
2025-7-30 19:32:11
羊夏菡
2025-7-30 19:32:11
- 政务大模型应用安全指引
- 政务大模型通用技术与应用支撑能力要求
- 转载学习: 政务大模型应用的21个安全要求(网安标委,2025.7)
规范明确,大模型在政务领域的主要应用包括:
- 对内 为日常办公提供支撑
- 对外 服务公众的政务办理需求
对应的核心风险为内容安全、数据安全和系统安全。为管控这些风险,企业在模型的选型、部署和运行各阶段都必须遵循相应安全要求,并配备“大模型安全护栏”和安全测评能力。
定义
常用安全标准
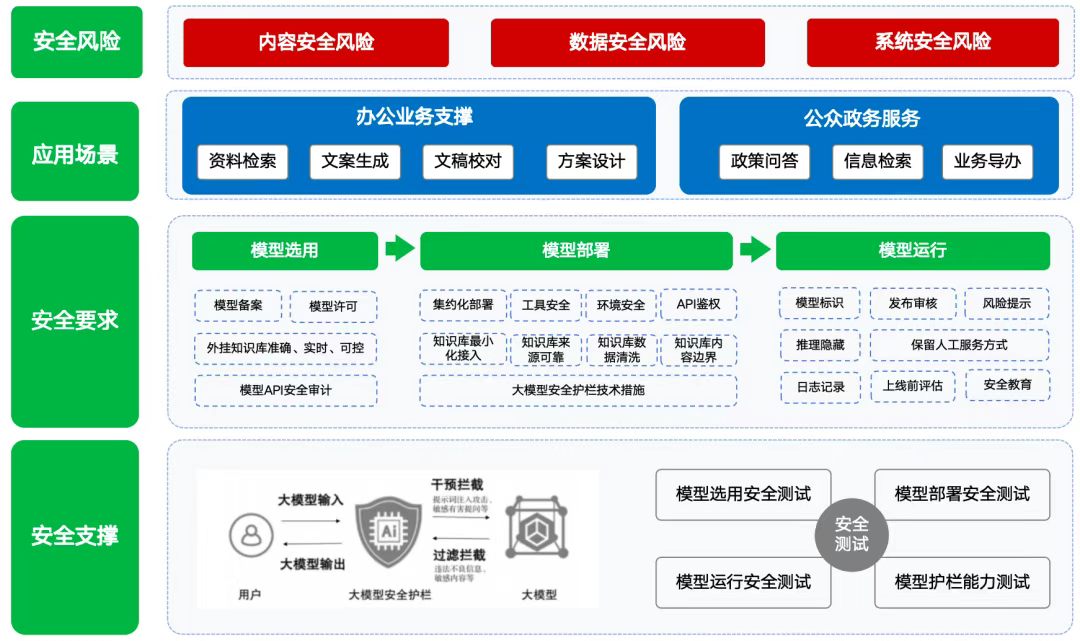
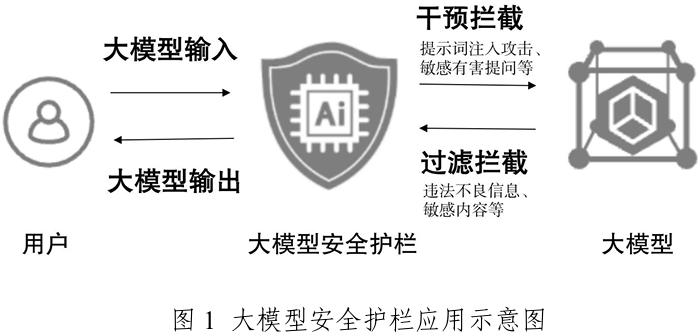
大模型安全护栏
用于约束和规范大模型应用行为的一系列策略、机制和技术手段,限制大模型输入输出内容或行为,防止生成有害、虚假、误导、敏感或不当内容。
政务大模型应用场景
基于大模型部署的办公助手应用,或将大模型嵌入政务办公系统,面向本单位人员提供资料检索、文案生成、文稿校对、方案设计、数据分析、创意生成等服务;
将大模型应用于政务服务热线、数字政务服务,面向公众提供智能化的政策问答、信息检索、业务导办等服务。
政务大模型安全风险
选用不可靠甚至违规大模型,数据集未有效筛选过滤,缺乏有效的输入输出管控措施,以及模型幻觉,引发生成传播错误有害信息、误导用户、模型应用被恶意利用等安全风险;
超范围接入使用大量政务数据,用户使用中上传内部工作资料、敏感个人信息,同时数据访问权限管控不严,引发政务数据和政务信息泄露风险;
在建设、部署、运维过程中,未有效落实政务信息系统网络安全防护要求,同时大模型应用成为网络攻击新入口,导致系统安全风险口扩大。
安全要求
模型选用
- 使用通过备案的商业大模型
- 使用开源大模型时,应对其完整性和安全测试
- 建议采用RAG,保证生成内容的准确、时效、可控性
- 调用大模型API服务时,应启用API鉴别机制,核实证书有效性
模型部署
- 按照政务信息系统建设要求,集中统一安全管理和体系化技术防护措施
- 应对部署大模型所需的软硬件、第三方工具等进行安全测试,确保没有已知漏洞
- 基础设施层面,应禁用必要的网络端口和功能服务
- 应用管理层面,应对交互接口进行身份验证和权限控制
- 对外挂知识库应遵循场景必要性原则
- 对外挂知识库应保证接入数据来源可靠、内容准确有效
- 应对外挂知识库的数据进行清洗过滤,按照标准对数据内容风险划分,去除数据中违法不良信息、错误信息、及涉及个人信息等敏感内容,要及进行脱敏等
- 对政务类应用,应保证外挂知识库数据内容不超过政务信息公开范围
- 应采用大模型安全护栏等防护技术,识别拦截违法不良信息、敏感有害问答、提示词注入攻击等,审核并管控输出内容不超过业务范围,对不当或超过范围提供采取拒答、固定答复等稳妥回应
模型运行
- 按照标准,做好大模型生成、合成内容标识
- 应用于涉及政务信息公开等权威信息发布的,应严格执行既有内部审核制度
- 应在大模型应用界面显著设置风险提示
- 对公众政务服务类应用,不应提供推理过程显示功能
- 对公众政务服务类应用,应保留人工服务方式
- 应记录大模型应用运行日志
- 大模型应用上线前,应开展安全测试验证
- 开展大模型应用安全教育培训
大模型安全护栏功能要求
针对大模型应用面临的生成输出违法不良信息、敏感有害问答,提示词注入攻击、资源消耗攻击、以及重要数据泄露等安全风险,建议采用大模型安全护栏对大模型输入输出进行识别、分析和管控。
大模型安全护栏功能要求:
- 支持识别提示词注入、越狱攻击、资源消耗攻击等对抗攻击指令并拦截,对抗性攻
击指令样本库宜覆盖典型的攻击模式并可持续更新。
- 具备与大模型应用所支持模态相匹配的输入输出内容识别能力,,具体包括文本识
别、图像识别、音频识别、视频识别、文件识别等。
- 具备大模型输入风险识别管控能力,干预拦截攻击行为、敏感有害问题,包括:
- 1)支持上下文关联分析,可对超长会话历史进行连贯性分析,可基于用户角色识
别拦截越权提问信息。
- 2)支持语义级分析能力,可自动识别分类违法不良信息,包括多模态隐晦违规内
容识别拦截,并提供自定义关键词过滤规则等定制化安全功能。
- 3)支持自动识别拦截个人信息等敏感内容。
- 具备大模型输出风险识别管控能力,过滤拦截输出内容中的违法不良信息、敏感内
容,包括:
- 1)配置脱敏规则,对大模型生成的敏感内容进行脱敏后输出。
- 2)过滤违法不良信息,对大模型生成的不当或超业务范围内容,采取限制输出或
代答、拒答等方式进行输出
- 3)支持建立代答知识库和拒答答案库,将识别的风险提问与标准回复进行映射,
对可预判问题提供标准答案,对用户进行正向引导。
- 4)支持代答知识库和拒答答案库的配置自定义扩展,可调整风险提问与回复的关
联关系。
- 5)支持代答知识库和拒答答案库按照实际需要及时更新。
- 具备日志留存和审计能力,支持记录行为主体、事件类型、事件时间以及系统行为、用户行为等,支持基于时间范围、请求用户等多维度查询和统计分析,定期对日志记录进行审计。
大模型安全护栏测试
- 构造包含对抗攻击指令的多样化测试题集,覆盖提示注入(如直接注入、间接注入、代码注入、多模态注入等)、越狱攻击(如角色扮演、输入混淆、上下文操纵等)、资源消耗攻击等攻击指令,验证大模型应用能否正确识别与分类。
- 核验大模型应用多模态输入输出内容识别能力。
- 支持文本输入输出内容的,至少测试全球主要语言及短、长文本场景识别,同义替换、中文繁简转换识别。
- 支持图像输入输出内容的,至少测试 JPEG、PNG、TIFF、SVG、GIF 常见主要图像格式及动图识别。
- 支持音频输入输出内容的,至少测试嘈杂环境下的识别,以及MP3、WAV、WMA、AAC等主要格式识别。
- 支持视频输入输出内容的,至少测试 MP4、AVI、MKV、MOV、WMV、H264、
HEVC 等常见主要格式识别。
- 支持文件输入输出内容的,至少测试 WPS、DOC、DOCX、PDF、XLS、XLSX、PPT、PPTX、JSON、JSONL、MD、RAR、ZIP、7Z 等常见主要格式识别。
- 通过交互问答测试核验大模型应用输入识别管控能力。
- 通过多轮对话构建上下文,对大模型分段引导和语义渗透,验证是否准确识别恶意诱导内容,是否准确识别不符合用户角色的输入内容。
- 构造包含违法不良信息的多样化测试题集,覆盖GB/T 45654—2025附录A中生成内容的主要安全风险,验证是否能正确识别与分类。验证是否可自定义配
置关键词过滤规则。
- 构造包含个人信息的多样化测试题集,验证能否正确识别敏感内容。验证是否可自定义配置重要数据识别规则。
- 通过交互问答测试核验大模型应用输出识别管控能力。
- 查看是否支持偏移、加密、重排、随机替换、掩码等脱敏规则配置。通过提交测试题,验证大模型应用在敏感内容输出时是否已进行脱敏处理。
- 构造违法不良信息、与本应用场景无关的测试题集,验证输出的内容是否包含违法不良信息、超业务范围内容。
- 若采用代答机制、拒答机制库,则核验已知风险问题类别与标准回复、拒答回复之间的映射关系,评估已提供代答、拒答内容的准确性和一致性。
- 若建立代答知识库、拒答答案库,查看代答知识库和拒答答案库的配置是否支持自定义扩展,允许调整风险类别与回复的关联关系。
- 核验对大模型日志留存及审计措施。
- 核查日志记录范围是否覆盖到大模型所有用户,核查是否记录每个用户的登录登出、操作行为、操作时间等。
- 核查日志留存时间是否满足至少6个月。
- 核查是否支持基于时间范围、请求用户、事件类型等多维度对日志进行查询和统计分析。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
|
|
|
|
|
|
相关推荐
|
|
|


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



