登录
/
注册
首页
论坛
其它
首页
科技
业界
安全
程序
广播
Follow
关于
博客
发1篇日志+1圆
记录
发1条记录+2圆币
发帖说明
登录
/
注册
账号
自动登录
找回密码
密码
登录
立即注册
搜索
搜索
关闭
CSDN热搜
程序园
精品问答
技术交流
资源下载
本版
帖子
用户
软件
问答
教程
代码
VIP网盘
VIP申请
网盘
联系我们
道具
勋章
任务
设置
我的收藏
退出
腾讯QQ
微信登录
返回列表
首页
›
业界区
›
业界
›
记录-内网部署vllm分布式推理DeepSeekR1:70b
记录-内网部署vllm分布式推理DeepSeekR1:70b
[ 复制链接 ]
皮仪芳
2025-6-2 22:50:54
背景
前段时间接到需求要在内网部署DeepSeekR1:70b,由于手里的服务器和显卡比较差(四台 四块Tesla T4- 16g显存的服务器),先后尝试了ollama、vllm、llamacpp等,最后选择用vllm的分布式推理来部署。
需要准备的资源
vllm的docker镜像(可以从docker hub 下载,使用docker save -o命令保存拿到内网服务器中)
run_cluster.sh脚本(用来启动docker镜像和进行ray通信,下面会贴上我目前在用的版本)
模型文件(huggingface下载,国内可以用hf-mirror镜像站),需要下载到所有分布式机器的磁盘中,最好保持存储路径一致。
nvidia驱动、cuda等是必备的,不提了
部署过程
载入vllm的docker镜像
docker load -i vllm.tar
编写脚本vi run_cluster.sh
所有机器都使用如下脚本
点击查看代码
``#!/bin/bash
# Check for minimum number of required arguments
if [ $# -lt 4 ]; then
echo "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"
exit 1
fi
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4
# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")
# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
# Define a function to cleanup on EXIT signal
cleanup() {
docker stop node
docker rm node
}
trap cleanup EXIT
# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# Run the docker command with the user specified parameters and additional arguments
#docker run \
# -d \
# --entrypoint /bin/bash \
docker run \
--entrypoint /bin/bash \
--network host \
--name node \
--shm-size 10.24g \
--gpus all \
-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \
"${ADDITIONAL_ARGS[@]}" \
"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"
复制代码
查看网卡信息
输入ip a
找到这台机器对应的编号,用在之后的启动命令中
启动脚本(每台机器都需要启动,选择任意一台为主节点,其他为工作节点)
启动命令:( --head为主机 --worker为其他机器使用,命令中的ip都需要填写主机的ip)
主机脚本
bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --head /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
工作机脚本
bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
后台运行
也可以通过nohup后台运行,如:nohup bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0 >/ray_file 2>&1 &
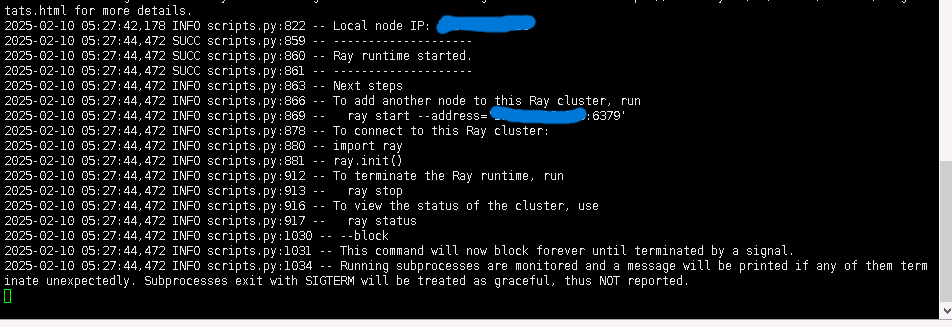
/data/vllm_model为你模型文件的位置,如下图则启动成功
所有都成功启动后可以使用任何一台机器的ssh会话,因为已经通信,所以哪台机器都可以启动vllm。注意不要关闭任何一台机器的run_cluster启动的页面,
使用docker ps 查看运行的镜像
进入镜像内部
输入docker exec -it 镜像号 /bin/bash进入
输入ray status可以查看当前通信状态
直接在docker中启动vllm
命令:vllm serve /model/DeepSeek-R1-Distill-Llama-70B --tensor-parallel-size 4 --pipeline-parallel-size 4 --dtype=float16
注:我的vllm运行命令中tensor-parallel对应每台服务器的gpu数,pipeline-parallel-size对应服务器数,--dtype=float16这个由于Tesla T4计算精度的问题需要添加这个配置降低模型的精度,如果显卡计算能力8.0以上可以不加这个配置。关于分布式并行的参数这里博主没有深究含义,如果有更好的使用方式也可以交流下。
参数含义
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
回复
本版积分规则
回帖并转播
回帖后跳转到最后一页
签约作者
程序园优秀签约作者
发帖
皮仪芳
2025-6-2 22:50:54
关注
0
粉丝关注
17
主题发布
板块介绍填写区域,请于后台编辑
财富榜{圆}
敖可
9984
黎瑞芝
9990
杭环
9988
4
猷咎
9988
5
凶契帽
9988
6
氛疵
9988
7
恐肩
9986
8
虽裘侪
9986
9
接快背
9986
10
里豳朝
9986
查看更多




 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



