大家好,我是小康。
写在前面
你知道吗?在高并发场景下,频繁的malloc和free操作就像是程序的"阿喀琉斯之踵",轻则拖慢系统响应,重则直接把服务器拖垮。
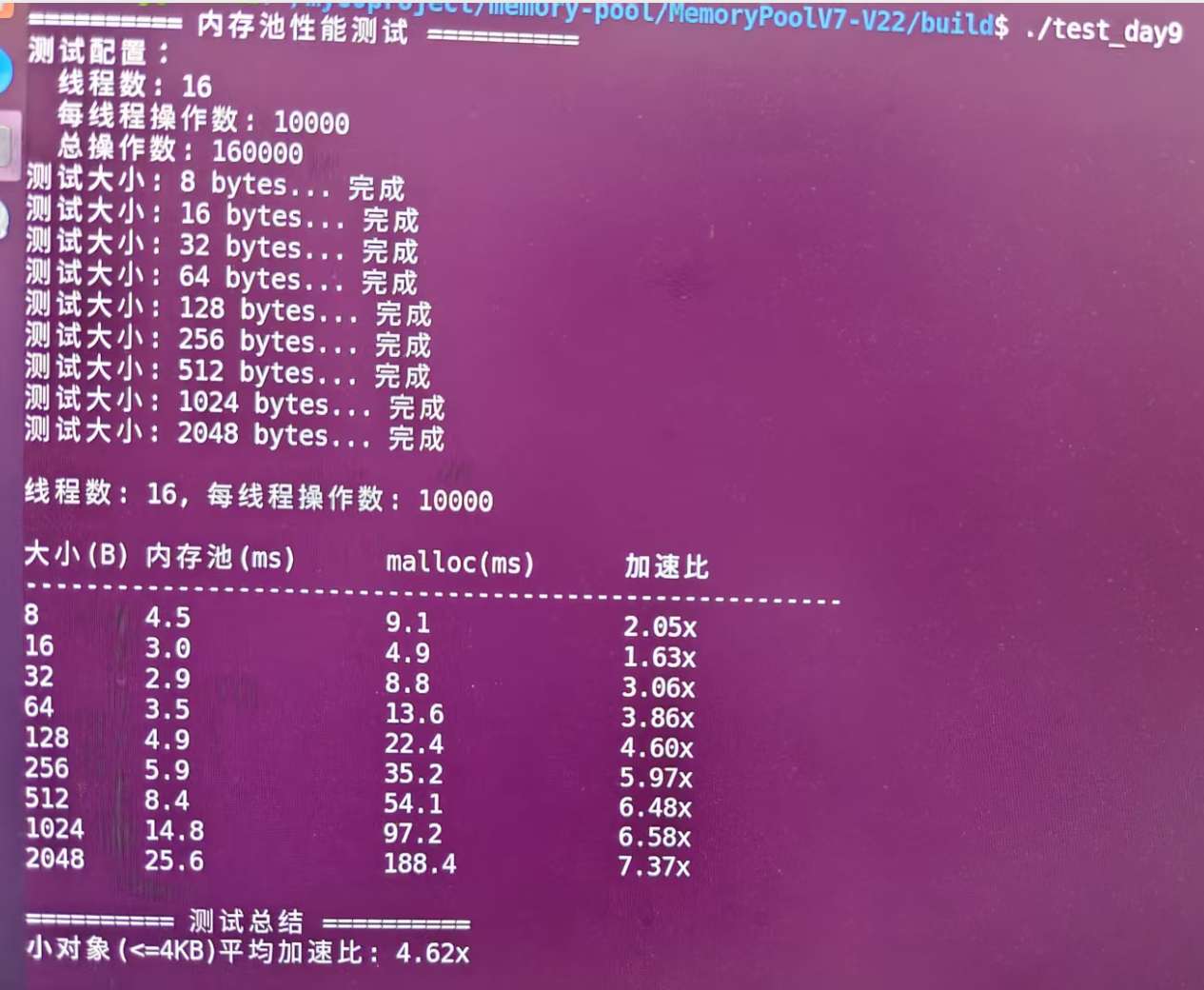
最近我从0到1实现了一个高性能内存池,经过严格的压测验证,在8B到2048B的分配释放场景下,性能相比传统的malloc/free平均快了4.5倍!今天就来给大家分享这个实现过程,相信看完后你也能写出自己的高性能内存池。
数据最有说服力,来看看实测结果:
看到了吗?相比标准malloc/free,平均性能提升4.62倍,最高达到7.37倍!
手把手教你实现C++高性能内存池,相比 malloc 性能提升7倍!
为什么需要内存池?
在开始撸代码之前,我们先来聊聊为什么要造这个轮子。
传统内存分配的痛点
你有没有遇到过这些情况:
- 频繁分配小对象:比如游戏服务器中每秒创建成千上万个临时对象
- 内存碎片化:明明还有很多空闲内存,但就是分配不出连续的大块
- 性能瓶颈:高并发场景下malloc成为系统的性能瓶颈
- 内存泄漏:忘记free导致的内存泄漏,让人头疼不已
这些问题的根源在于:系统级的内存分配器设计得太通用了。它要处理各种大小的内存请求,要考虑各种边界情况,这就导致了性能上的妥协。
内存池的优势
内存池就像是给程序开了个"专属食堂":
- 速度快:预先分配好内存,拿来就用,不用每次都找系统要
- 减少碎片:统一管理,按需切分,内存利用率更高
- 避免泄漏:集中管理,程序结束时统一释放
- 可控性强:自己的地盘自己做主,可以根据业务特点优化
设计思路:三层架构设计
经过大量调研和思考,我采用了类似TCMalloc的三层架构:- ┌─────────────────────────────────────────────────────────┐
- │ 应用程序 │
- └─────────────────────┬───────────────────────────────────┘
- │ ConcurrentAlloc() / ConcurrentFree()
- ┌─────────────────────▼───────────────────────────────────┐
- │ ThreadCache (线程缓存) │
- │ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
- │ │ 8B │ │16B │ │32B │ │... │ 每个线程独享 │
- │ │List │ │List │ │List │ │List │ │
- │ └─────┘ └─────┘ └─────┘ └─────┘ │
- └─────────────────────┬───────────────────────────────────┘
- │ 批量获取/归还
- ┌─────────────────────▼───────────────────────────────────┐
- │ CentralCache (中央缓存) │
- │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
- │ │ 8B Span │ │16B Span │ │32B Span │ 全局共享,桶锁 │
- │ │ List │ │ List │ │ List │ │
- │ └─────────┘ └─────────┘ └─────────┘ │
- └─────────────────────┬───────────────────────────────────┘
- │ 申请新Span
- ┌─────────────────────▼───────────────────────────────────┐
- │ PageHeap (页堆) │
- │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
- │ │ 1页 │ │ 2页 │ │ 4页 │ │ 8页 │ 管理大块内存 │
- │ │ Span │ │ Span │ │ Span │ │ Span │ │
- │ └──────┘ └──────┘ └──────┘ └──────┘ │
- └─────────────────────┬───────────────────────────────────┘
- │ 系统调用
- ┌─────────────────────▼───────────────────────────────────┐
- │ 操作系统 │
- │ (mmap/VirtualAlloc) │
- └─────────────────────────────────────────────────────────┘
这个设计的精妙之处在于分层解耦:
- ThreadCache:每个线程都有自己的缓存,分配时无需加锁,速度飞快
- CentralCache:当ThreadCache没有合适的内存块时,向CentralCache申请
- PageHeap:管理大块内存,当CentralCache也没有时,向系统申请内存
这样设计的好处是:大部分情况下分配操作都在ThreadCache完成,无锁且极快;只有在必要时才会涉及锁操作。
第一层:ThreadCache(线程本地缓存)
设计理念:每个线程拥有独立的内存缓存,消除锁竞争。- class ThreadCache {
- private:
- FreeList free_lists_[NFREELISTS]; // 208个不同大小的自由链表
- static thread_local ThreadCache* tls_thread_cache_;
-
- public:
- void* Allocate(size_t size);
- void Deallocate(void* ptr, size_t size);
- };
- 无锁设计:线程本地存储,天然线程安全
- 多级缓存:208个不同大小的自由链表
- 批量操作:与中心缓存批量交换,减少交互次数
第二层:CentralCache(中心分配器)
设计理念:所有线程共享的中心分配器,负责向ThreadCache提供内存。- class CentralCache {
- private:
- SpanList span_lists_[NFREELISTS]; // Span链表数组
- std::mutex mutexes_[NFREELISTS]; // 桶锁数组
-
- public:
- size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t size);
- void ReleaseListToSpans(void* start, size_t size);
- };
- 桶锁设计:每个大小类别独立锁,减少锁竞争
- Span管理:每个Span管理一组连续页面
- 批量分配:一次分配多个对象给ThreadCache
第三层:PageHeap(页堆管理器)
设计理念:管理大块内存页面,是系统内存和应用的桥梁。- class PageHeap {
- private:
- SpanList span_lists_[POWER_SLOTS]; // 只管理2的幂次页数
- PageMap2<PAGE_MAP_BITS> page_map_; // 页面到Span映射,采用基数树来管理
-
- public:
- Span* AllocateSpan(size_t n);
- void ReleaseSpanToPageHeap(Span* span);
- };
- 2的幂次优化:只分配1,2,4,8,16,32,64,128,256页的Span
- 智能分裂:大Span智能分裂成小Span
- 零开销释放:释放直接缓存,无需合并操作
核心数据结构设计
1. 自由链表(FreeList)
这是内存池的基础数据结构,将空闲内存块串成链表:- class FreeList {
- private:
- void* head_; // 链表头指针
- size_t size_; // 当前大小
- size_t max_size_; // 慢启动最大批量大小
-
- public:
- void Push(void* obj);
- void* Pop();
- void PushRange(void* start, void* end, size_t n);
- size_t PopRange(void*& start, void*& end, size_t n);
- };
- static inline void*& NextObj(void* obj) {
- return *(void**)obj; // 前8字节存储下一个块的地址
- }
Span是管理连续页面的核心结构:- struct Span {
- PageID page_id_; // 起始页号
- size_t n_; // 页数
- Span* next_; // 双向链表指针
- Span* prev_;
- size_t object_size_; // 切分的对象大小
- size_t use_count_; // 已分配对象数
- void* free_list_; // 切分后的自由链表
- bool is_used_; // 是否使用中
- };
1. 大小类别映射算法
将任意大小映射到固定的大小类别,这是性能的关键:
[code]static inline size_t RoundUp(size_t size) { if (size |


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



