登录
/
注册
首页
论坛
其它
首页
科技
业界
安全
程序
广播
Follow
关于
博客
发1篇日志+1圆
记录
发1条记录+2圆币
发帖说明
登录
/
注册
账号
自动登录
找回密码
密码
登录
立即注册
搜索
搜索
关闭
CSDN热搜
程序园
精品问答
技术交流
资源下载
本版
帖子
用户
软件
问答
教程
代码
VIP网盘
VIP申请
网盘
联系我们
道具
勋章
任务
设置
我的收藏
退出
腾讯QQ
微信登录
返回列表
首页
›
业界区
›
安全
›
深入 PostgreSQL 内部:5 个关键阶段拆解查询处理全流程 ...
深入 PostgreSQL 内部:5 个关键阶段拆解查询处理全流程
[ 复制链接 ]
慷规扣
2025-6-11 13:06:09
引言
当您向 PostgreSQL 发送查询时,后端会经历多个处理阶段。每个阶段承担着不同的职责,以确保您能在最短时间内获得准确响应。虽然这些阶段可能庞大而复杂,但理解它们在查询处理中的角色对 PostgreSQL 开发者至关重要。本文将概述每个查询处理阶段的功能及其在 PostgreSQL 架构中的重要性。
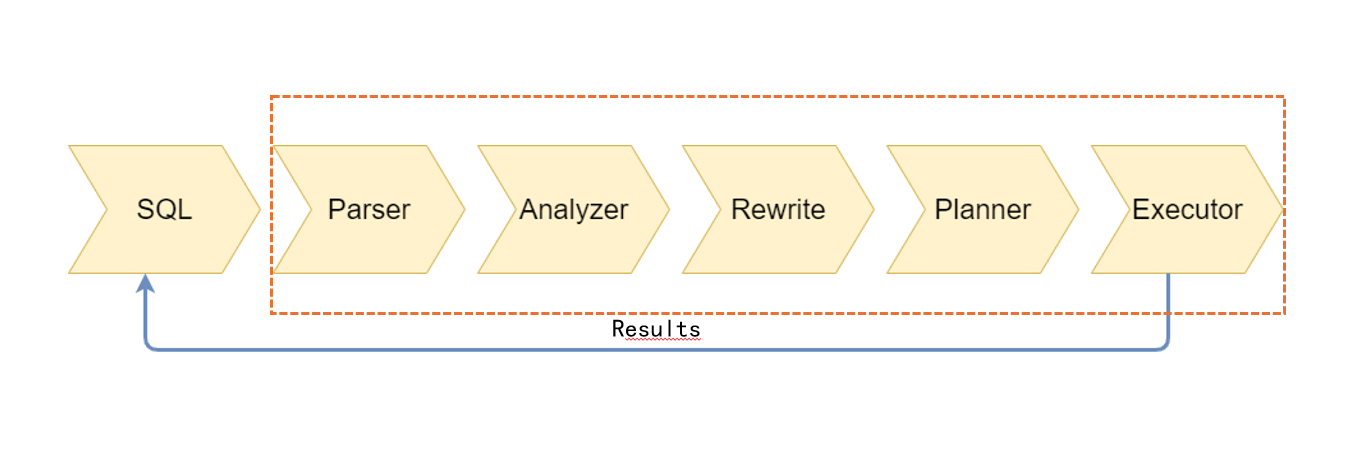
5 个查询处理阶段
解析器(Parser)
PostgreSQL 的解析器使用 lex(Flex 词法分析器)和 yacc(Bison 解析器)工具创建。这些工具通过正则表达式定义文件生成对应的 C 语言源代码结构,生成的源文件位于 src/backend/parser 目录下,并在编译 PostgreSQL 时通过 make 自动生成。
简要总结:
检查语法错误
生成解析树(parse tree)
使用 Flex 和 Bison 解析查询语法
入口地址:parser/parser.c
分析器(Analyzer)
分析器负责验证解析器生成的 raw_parsetree 结构。例如:检查表名有效性、插入数据类型匹配和字段存在性,最终将对象名称转换为内部 OID(对象标识符),并生成查询树(query tree)。
简要总结:
执行语义分析
验证数据库对象(表、列等)
将名称转换为内部 OID
生成查询树
入口地址:parser/analyze.c
重写器(Rewriter)
重写器(Rewriter)的主要功能是对分析器输出的查询树进行重写和优化。
例如:检查是否引用了其他 VIEW 或 RULE 结构。如果有,它将重写语句并将 VIEW 和 RULE 转换为相应的语句。它输出一个优化后的查询树供计划器模块使用。
简要总结:
负责在需要时重写查询
如果查询访问了 VIEW 或 RULE 对象,它将根据这些 VIEW 或 RULE 的定义进行扩展(或重写)
入口地址:rewrite/rewriteHandler.c
查询规划器(Planner)
负责执行语句成本估算和生成优化的查询计划。根据语句类型、表结构、是否有索引及其大小等,计算不同的执行方法(也叫路径)。
每个路径都有一个估算成本,成本最低的路径被认为是最优查询计划。最终,生成一个最优查询计划(PlannedStmt 结构),并将其发送给执行器模块(executor)执行。
PostgreSQL 中的规划器模块相对复杂。大功能的开发通常需要对规划器有一定的理解,甚至需要对其进行修改。
get_relation_info() 调用:
plancat.c 中的 get_relation_info() 是规划器成本估算中的一个重要函数。它告诉规划器:
表中有多少页
数据(元组)有多少
有多少索引
哪一列是索引键
是否有外部表
其他信息
这些信息是规划器进行成本估算的基础。它通过访问方法获取这些信息:
堆访问方法(Heap Access Method)— 获取数据表信息
索引访问方法(Index Access Method)— 获取与索引相关的信息
简要总结:
负责生成执行计划
确定所有可能的获取结果的方法(或路径)
选择能以最短时间完成查询的最佳方法
入口地址:optimizer/plan/planner.c
执行器(Executor)
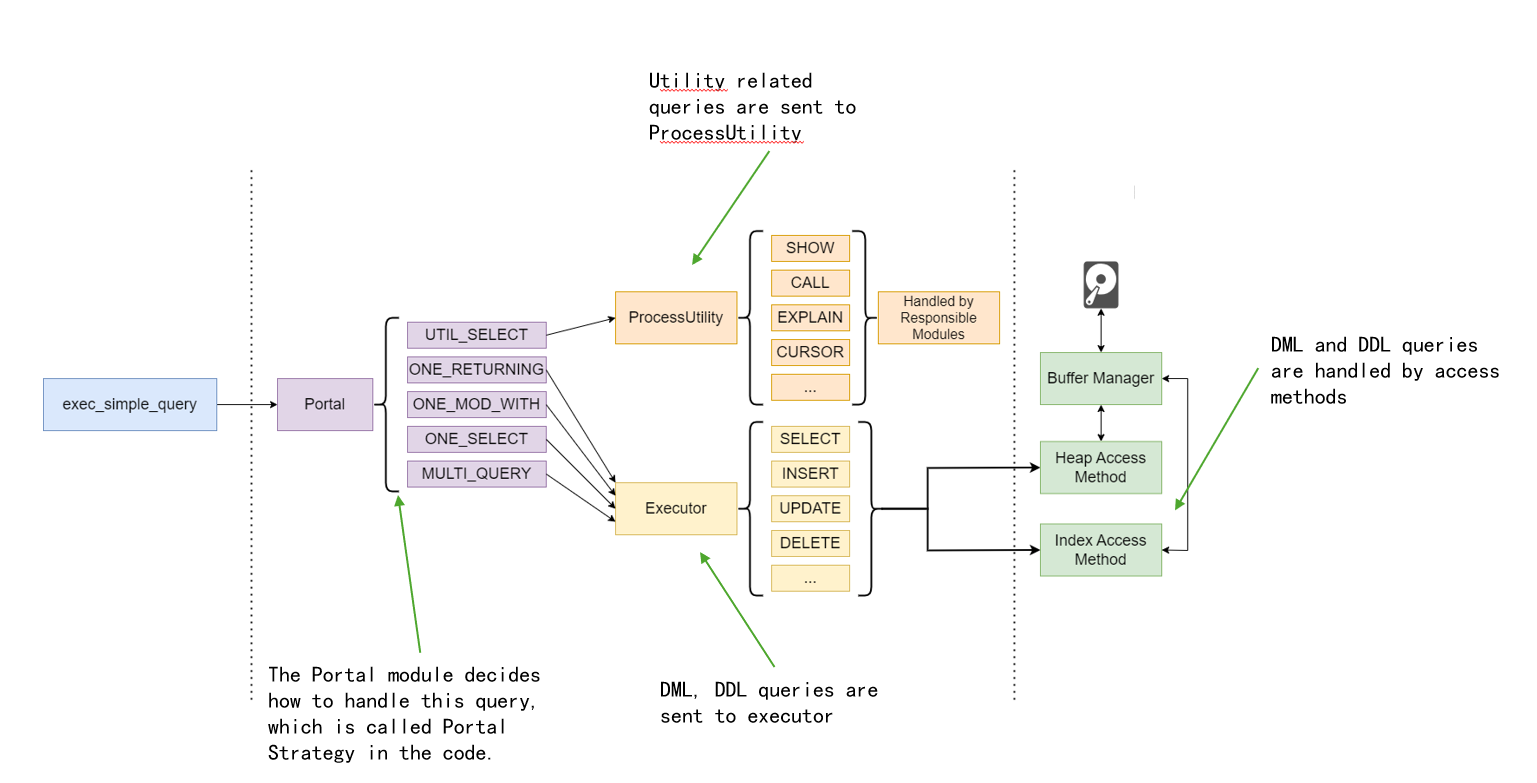
执行器的主要目的是运行由规划器生成的执行计划。它实际上由 portal 模块控制,后者是实际执行的促进者。根据执行计划的性质,可能会调用 executor 或 processUtility:
请参阅下面的插图了解 ProcessUtility 和 Executor 的职责。
简要总结:
根据执行计划执行查询
访问 PostgreSQL 后端中的多个其他模块来完成查询
入口地址:executor/execMain.c
执行器之后发生了什么?
执行器模块依赖于其他几个模块来完成查询。它很可能会与访问方法层(表和索引访问方法)接口,该层负责实际的数据操作(读取或写入)或表和索引数据。访问方法层又依赖于其他模块(缓冲区管理器和存储管理器)来处理实际的数据读写。
请参阅下面的图示:
查询处理生命周期
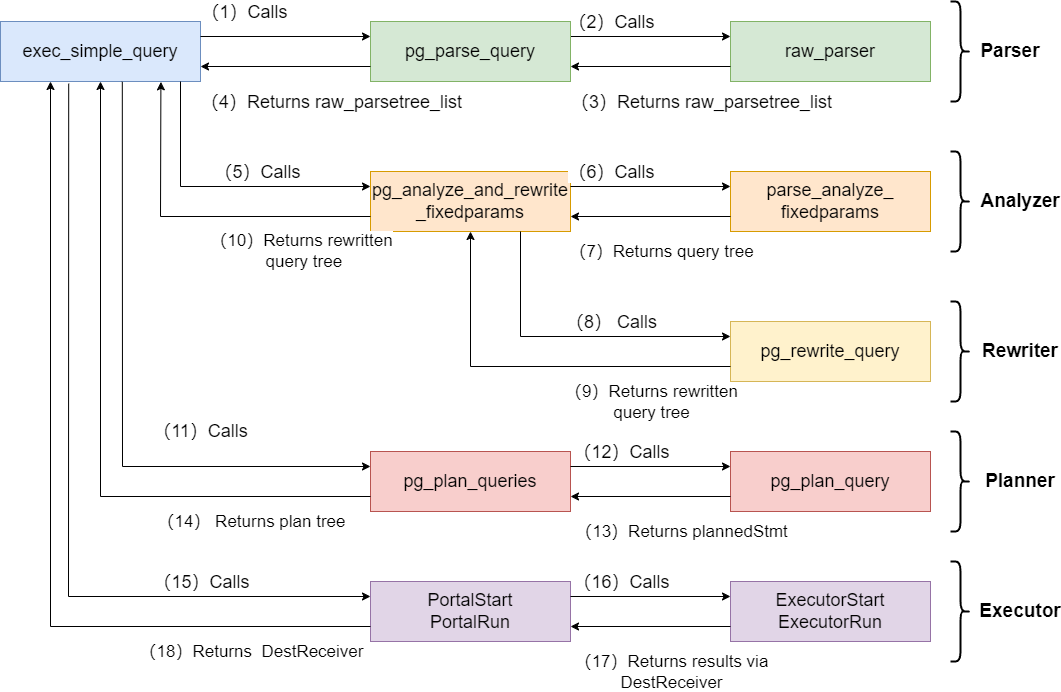
从源代码的角度来看,查询处理是通过调用 exec_simple_query() 函数开始的。除非你使用游标或扩展查询协议,否则你通过 psql 发出的绝大多数查询都是从这里开始的。
在 exec_simple_query() 中,它会调用每个查询处理阶段提供的入口函数,最终返回 DestReceiver 对象。
请参阅下面的插图:
Portal – DestReceiver
无论查询最终是进入 ProcessUtility 还是 Executor,它最终都会返回一个或多个结果。这些结果存储在 TupleTableSlot(简称 TTS)结构中,其中包含一个或多个元组作为结果。
元组可以理解为行数据。一个元组中可能包含多个值,分别对应相应的列。PostgreSQL 目前只支持 Heap 作为元组类型,也称为 HeapTuple。Heap 的行为定义在 HeapAccessMethod 中。
TTS 存储在 DestReceiver 结构中,它告诉 Portal 模块结果应该呈现的位置,标志着查询处理的结束。
本文由博客一文多发平台 OpenWrite 发布!
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
回复
本版积分规则
回帖并转播
回帖后跳转到最后一页
签约作者
程序园优秀签约作者
发帖
慷规扣
2025-6-11 13:06:09
关注
0
粉丝关注
18
主题发布
板块介绍填写区域,请于后台编辑
财富榜{圆}
敖可
9984
黎瑞芝
9990
杭环
9988
4
猷咎
9988
5
凶契帽
9988
6
接快背
9988
7
氛疵
9988
8
恐肩
9986
9
虽裘侪
9986
10
里豳朝
9986
查看更多




 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



