CSDN热搜
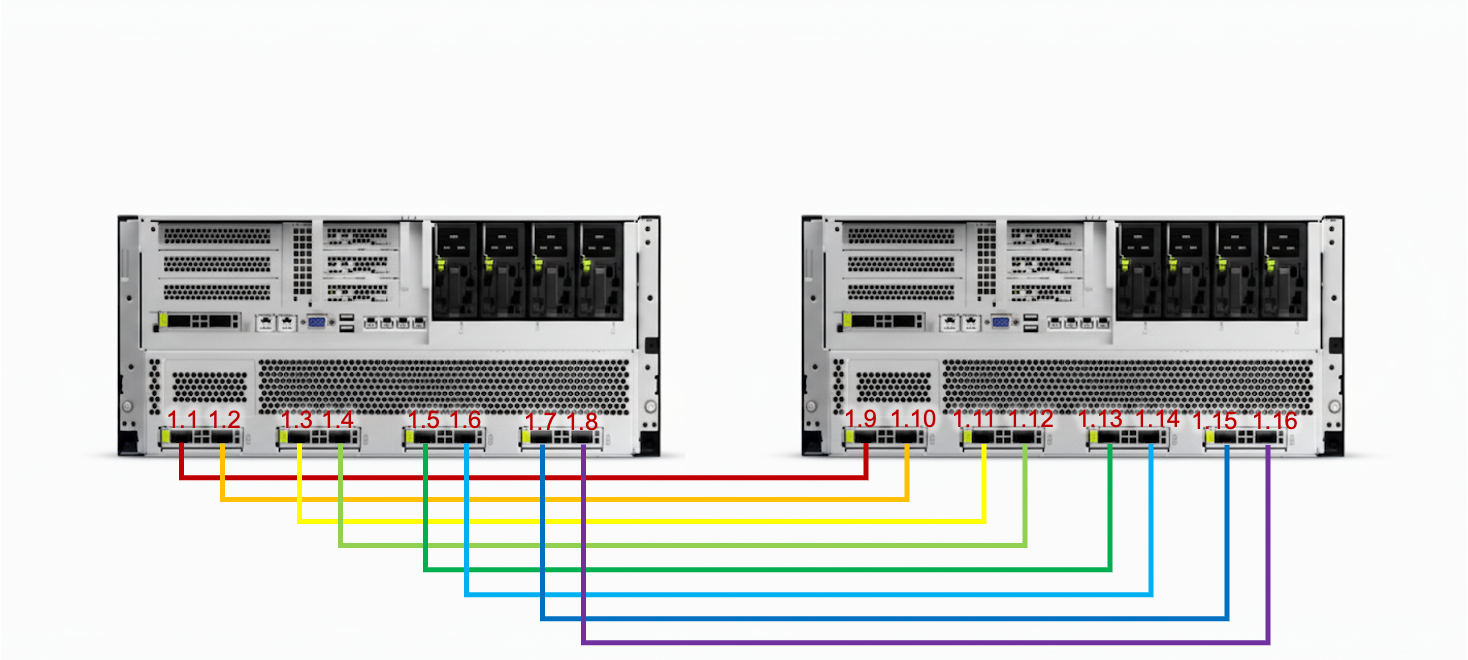
启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为 /data/models,可按实际修改,多节点需要统一路径
(1) 启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为 /data/models,可按实际修改,多节点需要统一路径 (2) http:// 表示 GPUStack 的访问地址,默认为节点1的 IP 地址 + 80 端口 (3) 为在节点1通过 docker exec gpustack cat /var/lib/gpustack/token 命令获得的认证 Token
如果觉得对你有帮助,欢迎点赞、转发、关注。
使用道具 举报
本版积分规则 回帖并转播 回帖后跳转到最后一页
程序园优秀签约作者
0
粉丝关注
17
主题发布










 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



