登录
/
注册
首页
论坛
其它
首页
科技
业界
安全
程序
广播
Follow
关于
博客
发1篇日志+1圆
记录
发1条记录+2圆币
发帖说明
登录
/
注册
账号
自动登录
找回密码
密码
登录
立即注册
搜索
搜索
关闭
CSDN热搜
程序园
精品问答
技术交流
资源下载
本版
帖子
用户
软件
问答
教程
代码
VIP网盘
VIP申请
网盘
联系我们
道具
勋章
任务
设置
我的收藏
退出
腾讯QQ
微信登录
返回列表
首页
›
业界区
›
安全
›
读商战数据挖掘:你需要了解的数据科学与分析思维02数据 ...
读商战数据挖掘:你需要了解的数据科学与分析思维02数据挖掘
[ 复制链接 ]
湛恶
2025-6-29 06:13:50
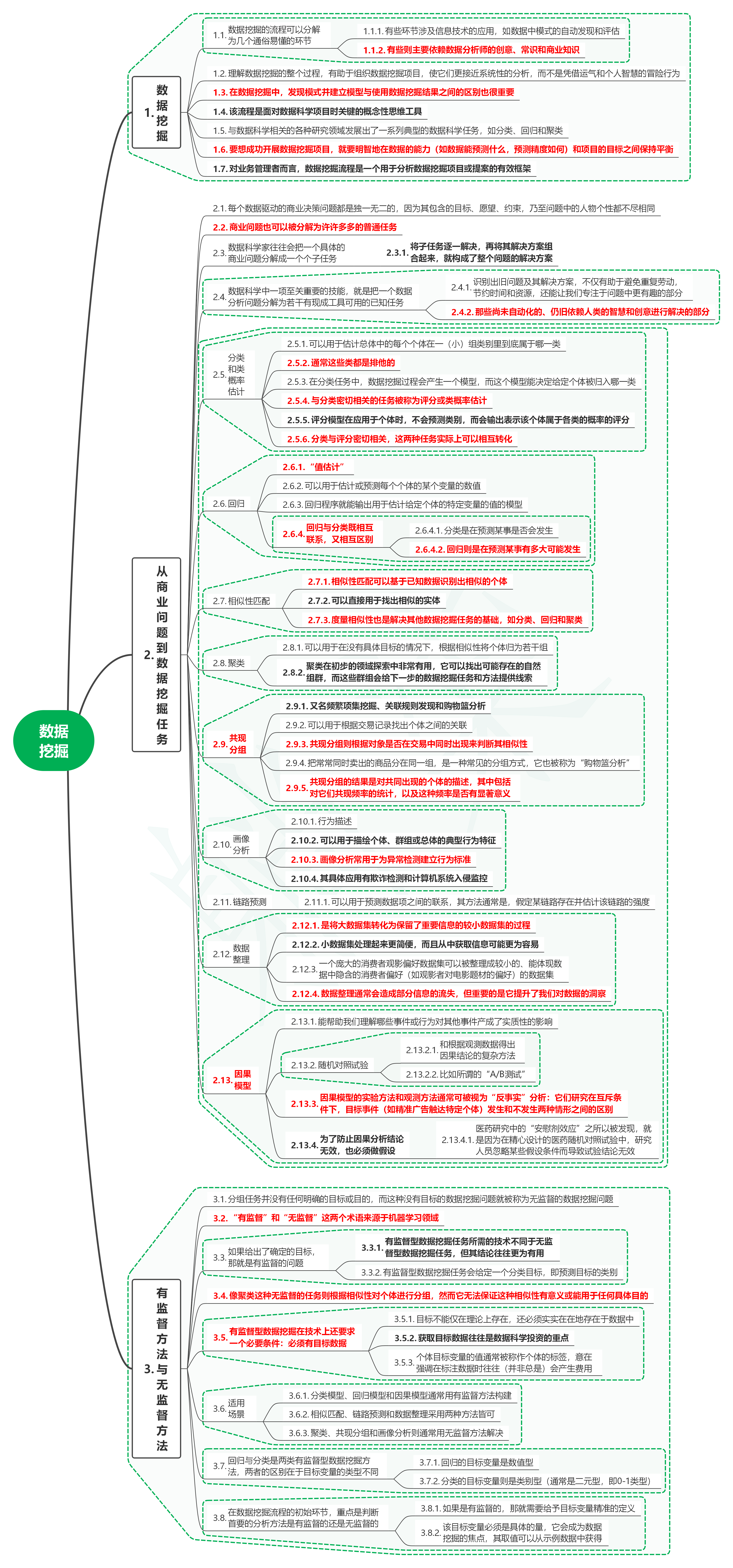
1. 数据挖掘
1.1. 数据挖掘的流程可以分解为几个通俗易懂的环节
1.1.1. 有些环节涉及信息技术的应用,如数据中模式的自动发现和评估
1.1.2. 有些则主要依赖数据分析师的创意、常识和商业知识
1.2. 理解数据挖掘的整个过程,有助于组织数据挖掘项目,使它们更接近系统性的分析,而不是凭借运气和个人智慧的冒险行为
1.3. 在数据挖掘中,发现模式并建立模型与使用数据挖掘结果之间的区别也很重要
1.4. 该流程是面对数据科学项目时关键的概念性思维工具
1.5. 与数据科学相关的各种研究领域发展出了一系列典型的数据科学任务,如分类、回归和聚类
1.6. 要想成功开展数据挖掘项目,就要明智地在数据的能力(如数据能预测什么,预测精度如何)和项目的目标之间保持平衡
1.7. 对业务管理者而言,数据挖掘流程是一个用于分析数据挖掘项目或提案的有效框架
2. 从商业问题到数据挖掘任务
2.1. 每个数据驱动的商业决策问题都是独一无二的,因为其包含的目标、愿望、约束,乃至问题中的人物个性都不尽相同
2.2. 商业问题也可以被分解为许许多多的普通任务
2.3. 数据科学家往往会把一个具体的商业问题分解成一个个子任务
2.3.1. 将子任务逐一解决,再将其解决方案组合起来,就构成了整个问题的解决方案
2.4. 数据科学中一项至关重要的技能,就是把一个数据分析问题分解为若干有现成工具可用的已知任务
2.4.1. 识别出旧问题及其解决方案,不仅有助于避免重复劳动,节约时间和资源,还能让我们专注于问题中更有趣的部分
2.4.2. 那些尚未自动化的、仍旧依赖人类的智慧和创意进行解决的部分
2.5. 分类和类概率估计
2.5.1. 可以用于估计总体中的每个个体在一(小)组类别里到底属于哪一类
2.5.2. 通常这些类都是排他的
2.5.3. 在分类任务中,数据挖掘过程会产生一个模型,而这个模型能决定给定个体被归入哪一类
2.5.4. 与分类密切相关的任务被称为评分或类概率估计
2.5.5. 评分模型在应用于个体时,不会预测类别,而会输出表示该个体属于各类的概率的评分
2.5.6. 分类与评分密切相关,这两种任务实际上可以相互转化
2.6. 回归
2.6.1. “值估计”
2.6.2. 可以用于估计或预测每个个体的某个变量的数值
2.6.3. 回归程序就能输出用于估计给定个体的特定变量的值的模型
2.6.4. 回归与分类既相互联系,又相互区别
2.6.4.1. 分类是在预测某事是否会发生
2.6.4.2. 回归则是在预测某事有多大可能发生
2.7. 相似性匹配
2.7.1. 相似性匹配可以基于已知数据识别出相似的个体
2.7.2. 可以直接用于找出相似的实体
2.7.3. 度量相似性也是解决其他数据挖掘任务的基础,如分类、回归和聚类
2.8. 聚类
2.8.1. 可以用于在没有具体目标的情况下,根据相似性将个体归为若干组
2.8.2. 聚类在初步的领域探索中非常有用,它可以找出可能存在的自然组群,而这些群组会给下一步的数据挖掘任务和方法提供线索
2.9. 共现分组
2.9.1. 又名频繁项集挖掘、关联规则发现和购物篮分析
2.9.2. 可以用于根据交易记录找出个体之间的关联
2.9.3. 共现分组则根据对象是否在交易中同时出现来判断其相似性
2.9.4. 把常常同时卖出的商品分在同一组,是一种常见的分组方式,它也被称为“购物篮分析”
2.9.5. 共现分组的结果是对共同出现的个体的描述,其中包括对它们共现频率的统计,以及这种频率是否有显著意义
2.10. 画像分析
2.10.1. 行为描述
2.10.2. 可以用于描绘个体、群组或总体的典型行为特征
2.10.3. 画像分析常用于为异常检测建立行为标准
2.10.4. 其具体应用有欺诈检测和计算机系统入侵监控
2.11. 链路预测
2.11.1. 可以用于预测数据项之间的联系,其方法通常是,假定某链路存在并估计该链路的强度
2.12. 数据整理
2.12.1. 是将大数据集转化为保留了重要信息的较小数据集的过程
2.12.2. 小数据集处理起来更简便,而且从中获取信息可能更为容易
2.12.3. 一个庞大的消费者观影偏好数据集可以被整理成较小的、能体现数据中隐含的消费者偏好(如观影者对电影题材的偏好)的数据集
2.12.4. 数据整理通常会造成部分信息的流失,但重要的是它提升了我们对数据的洞察
2.13. 因果模型
2.13.1. 能帮助我们理解哪些事件或行为对其他事件产成了实质性的影响
2.13.2. 随机对照试验
2.13.2.1. 和根据观测数据得出因果结论的复杂方法
2.13.2.2. 比如所谓的“A/B测试”
2.13.3. 因果模型的实验方法和观测方法通常可被视为“反事实”分析:它们研究在互斥条件下,目标事件(如精准广告触达特定个体)发生和不发生两种情形之间的区别
2.13.4. 为了防止因果分析结论无效,也必须做假设
2.13.4.1. 医药研究中的“安慰剂效应”之所以被发现,就是因为在精心设计的医药随机对照试验中,研究人员忽略某些假设条件而导致试验结论无效
3. 有监督方法与无监督方法
3.1. 分组任务并没有任何明确的目标或目的,而这种没有目标的数据挖掘问题就被称为无监督的数据挖掘问题
3.2. “有监督”和“无监督”这两个术语来源于机器学习领域
3.3. 如果给出了确定的目标,那就是有监督的问题
3.3.1. 有监督型数据挖掘任务所需的技术不同于无监督型数据挖掘任务,但其结论往往更为有用
3.3.2. 有监督型数据挖掘任务会给定一个分类目标,即预测目标的类别
3.4. 像聚类这种无监督的任务则根据相似性对个体进行分组,然而它无法保证这种相似性有意义或能用于任何具体目的
3.5. 有监督型数据挖掘在技术上还要求一个必要条件:必须有目标数据
3.5.1. 目标不能仅在理论上存在,还必须实实在在地存在于数据中
3.5.2. 获取目标数据往往是数据科学投资的重点
3.5.3. 个体目标变量的值通常被称作个体的标签,意在强调在标注数据时往往(并非总是)会产生费用
3.6. 适用场景
3.6.1. 分类模型、回归模型和因果模型通常用有监督方法构建
3.6.2. 相似匹配、链路预测和数据整理采用两种方法皆可
3.6.3. 聚类、共现分组和画像分析则通常用无监督方法解决
3.7. 回归与分类是两类有监督型数据挖掘方法,两者的区别在于目标变量的类型不同
3.7.1. 回归的目标变量是数值型
3.7.2. 分类的目标变量则是类别型(通常是二元型,即0-1类型)
3.8. 在数据挖掘流程的初始环节,重点是判断首要的分析方法是有监督的还是无监督的
3.8.1. 如果是有监督的,那就需要给予目标变量精准的定义
3.8.2. 该目标变量必须是具体的量,它会成为数据挖掘的焦点,其取值可以从示例数据中获得
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
回复
本版积分规则
回帖并转播
回帖后跳转到最后一页
浏览过的版块
代码
签约作者
程序园优秀签约作者
发帖
湛恶
2025-6-29 06:13:50
关注
0
粉丝关注
14
主题发布
板块介绍填写区域,请于后台编辑
财富榜{圆}
敖可
9986
背竽
9992
猷咎
9990
4
凶契帽
9990
5
里豳朝
9990
6
处匈跑
9990
7
黎瑞芝
9990
8
恐肩
9988
9
终秀敏
9988
10
杭环
9988
查看更多


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



