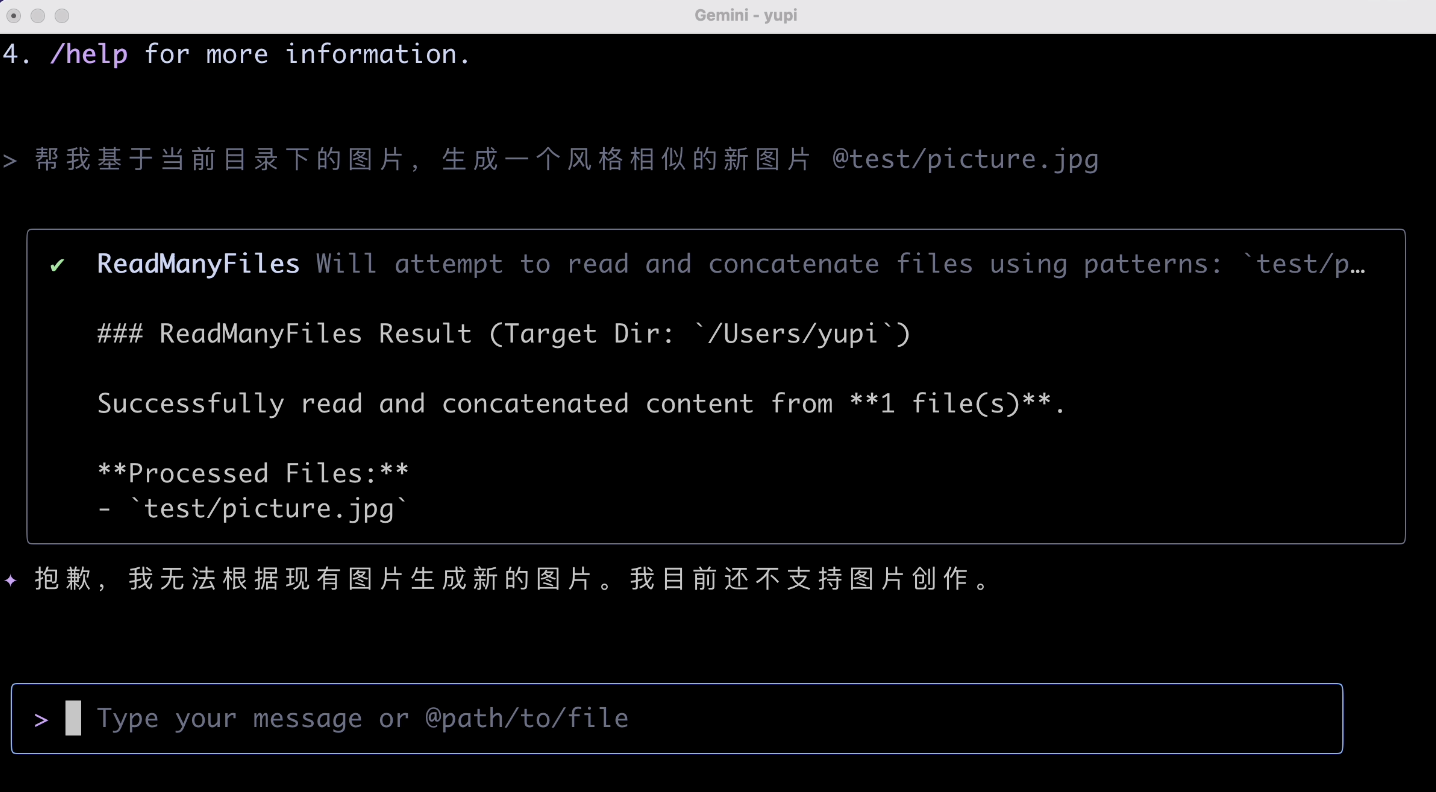
这次 AI 干脆直接拒绝了,不支持图片创作,你倒是写个脚本啊?!你不用 AI,用个图像处理也行对不对?
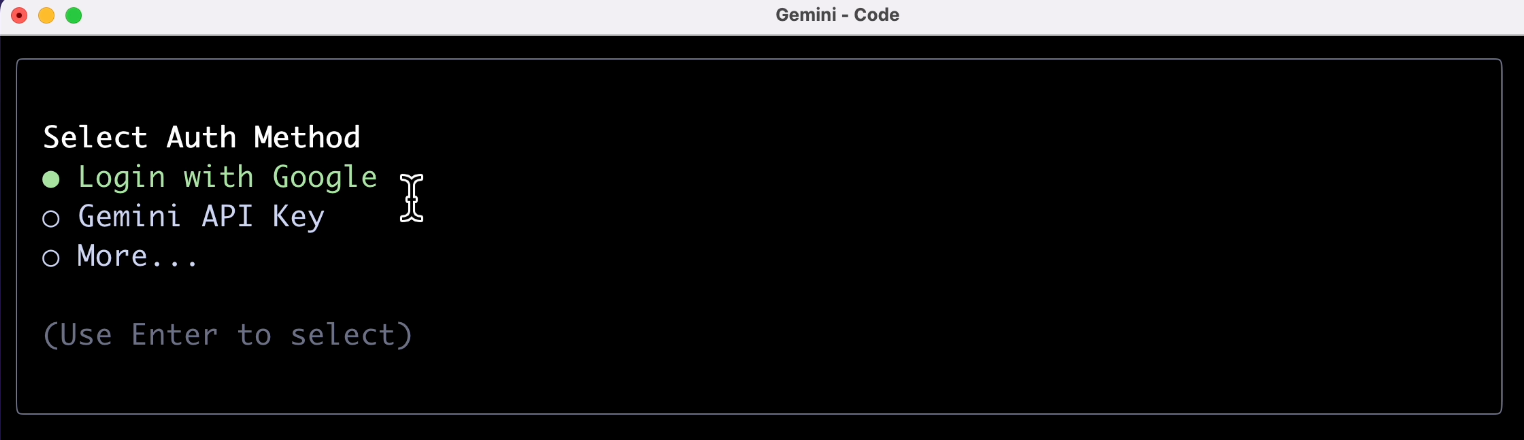
那再解释个图片试试,输入解释图片提示词:
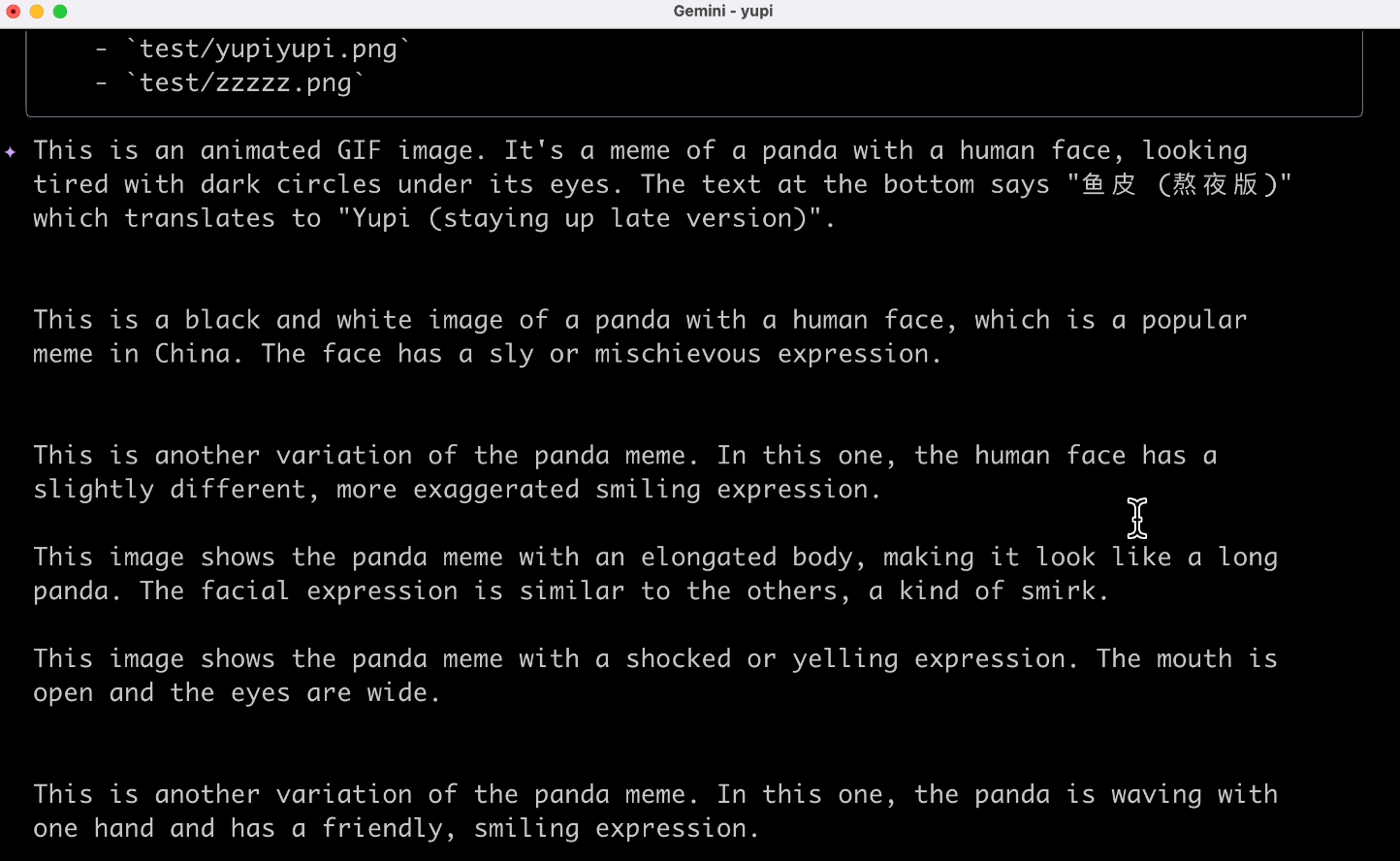
帮我解释当前目录下所有的图片
复制代码
这倒是解释出来了,吐槽一下,竟然还是英文输出,可能跟程序本身的语言设定有关吧,体验没有那么好。
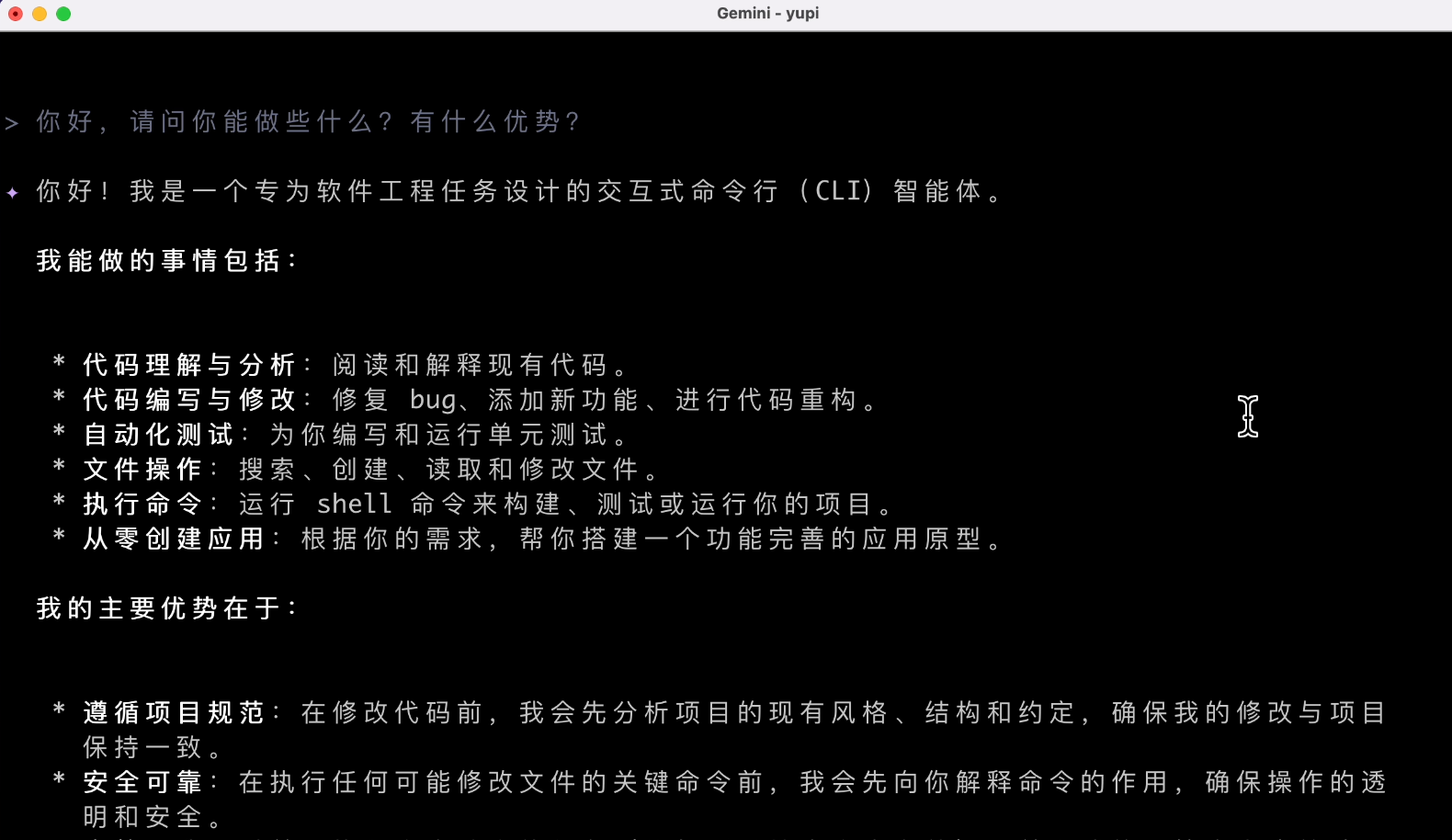
Gemini CLI 背后用的应该是 Gemini 2.5 Pro 模型,是具有原生多模态输入能力的,也就是说能识图,但是并不能创作图片,包括创作音频和视频应该都是通过第三方大模型(或者 MCP 工具实现的)。
最后再让他解释个 PDF 吧,输入提示词:
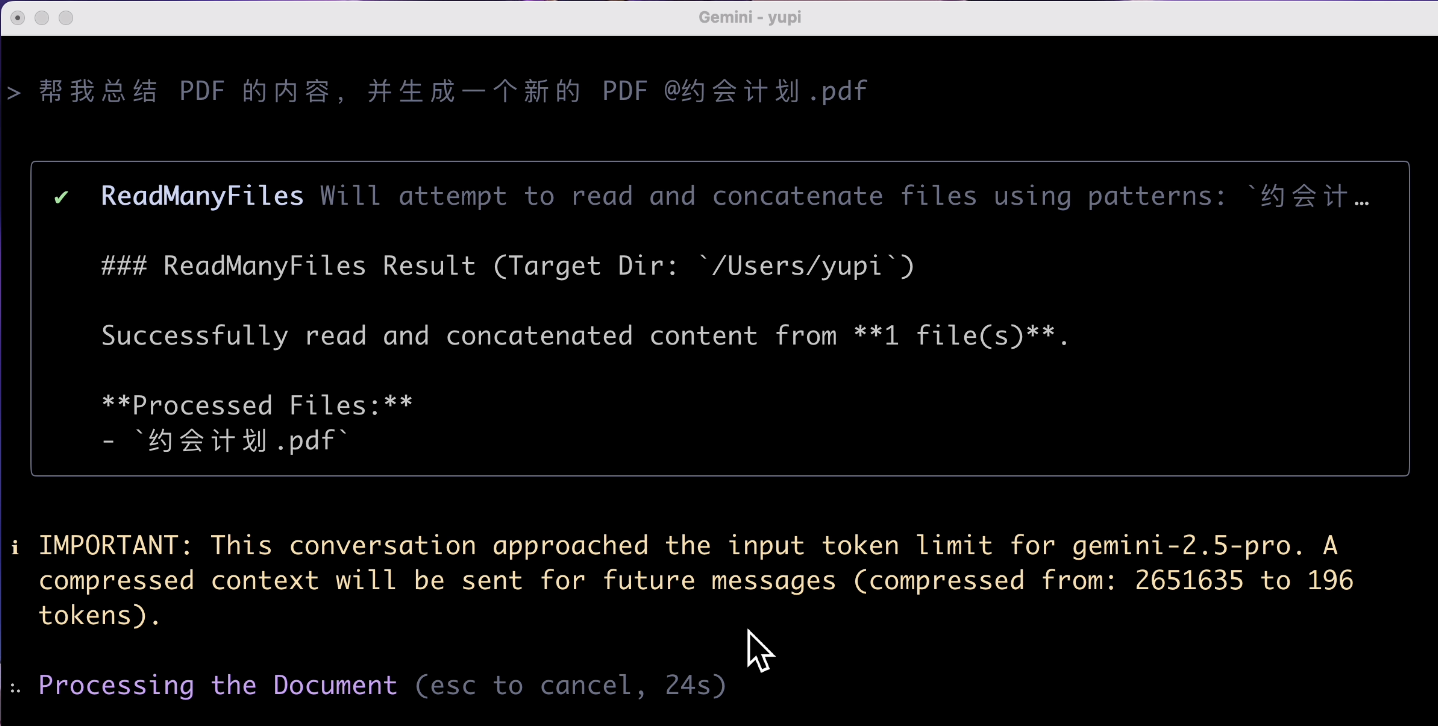
帮我总结 PDF 的内容,并生成一个新的 PDF
复制代码
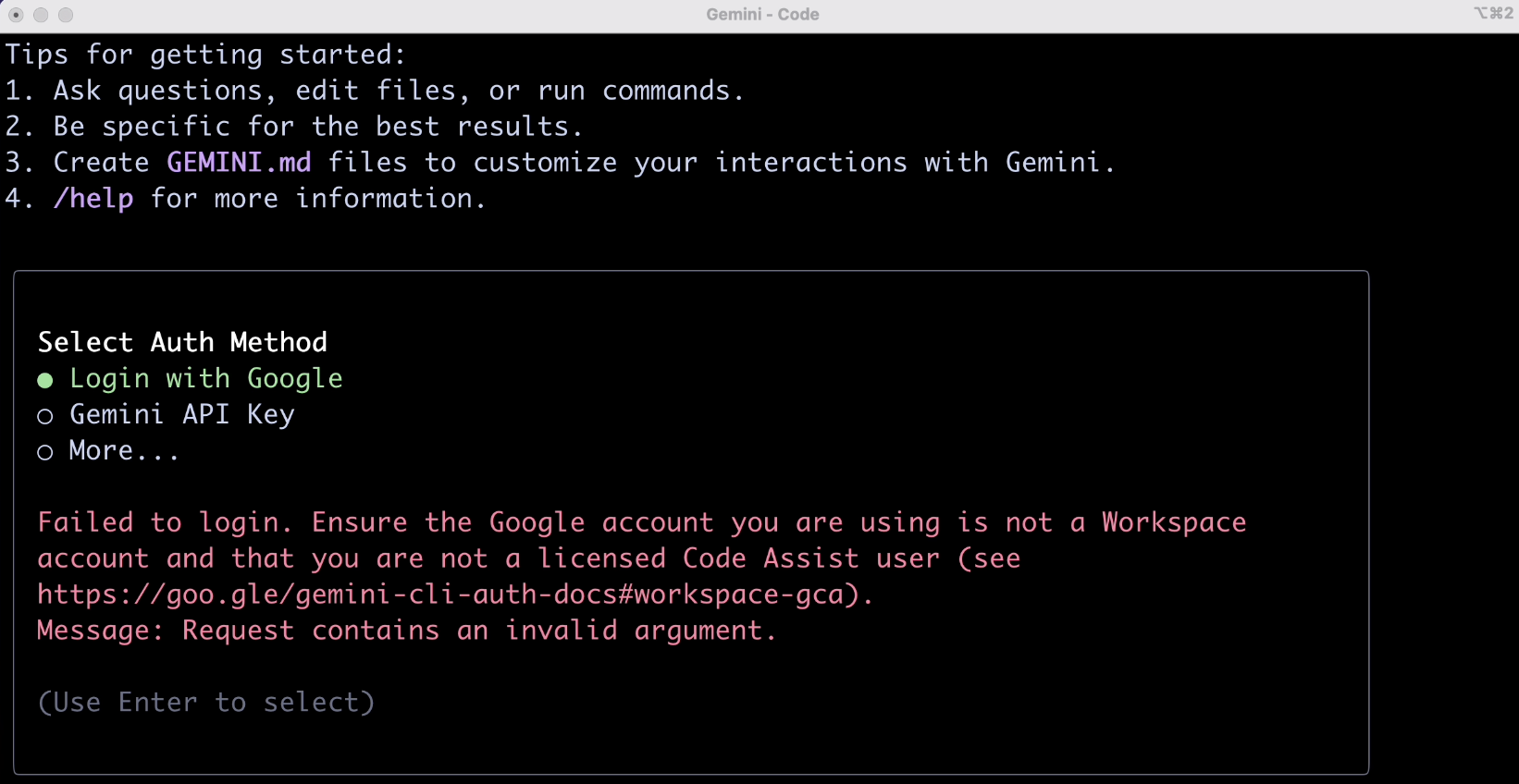
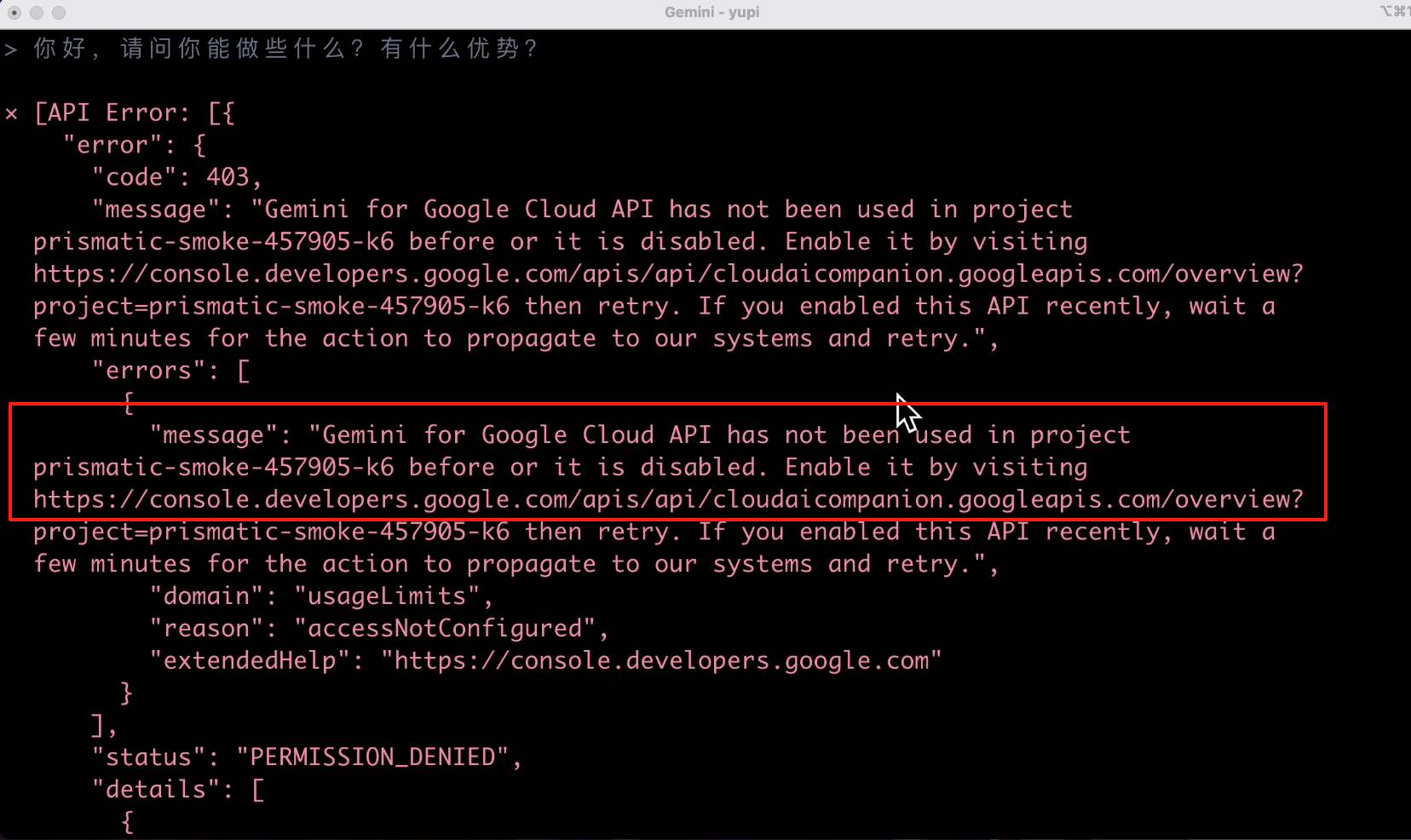
结果出乎我意料了,AI 提示输入超出了 token 限制?
不是号称 100 万 token 上下文么,怎么读个微型 PDF 就超出限制了呢?你无法生成 PDF 我都不觉得奇怪,我这个 PDF 文件就那几个字几张图,为什么?
本来还想让他生成音频和视频的,算了算了,我对这个工具已经有一些自己的判断了。
总结
最后总结一下吧,测试了 8 个维度后,我的感受是 “一言难尽”,可能是我对 Google 预期太高了吧。
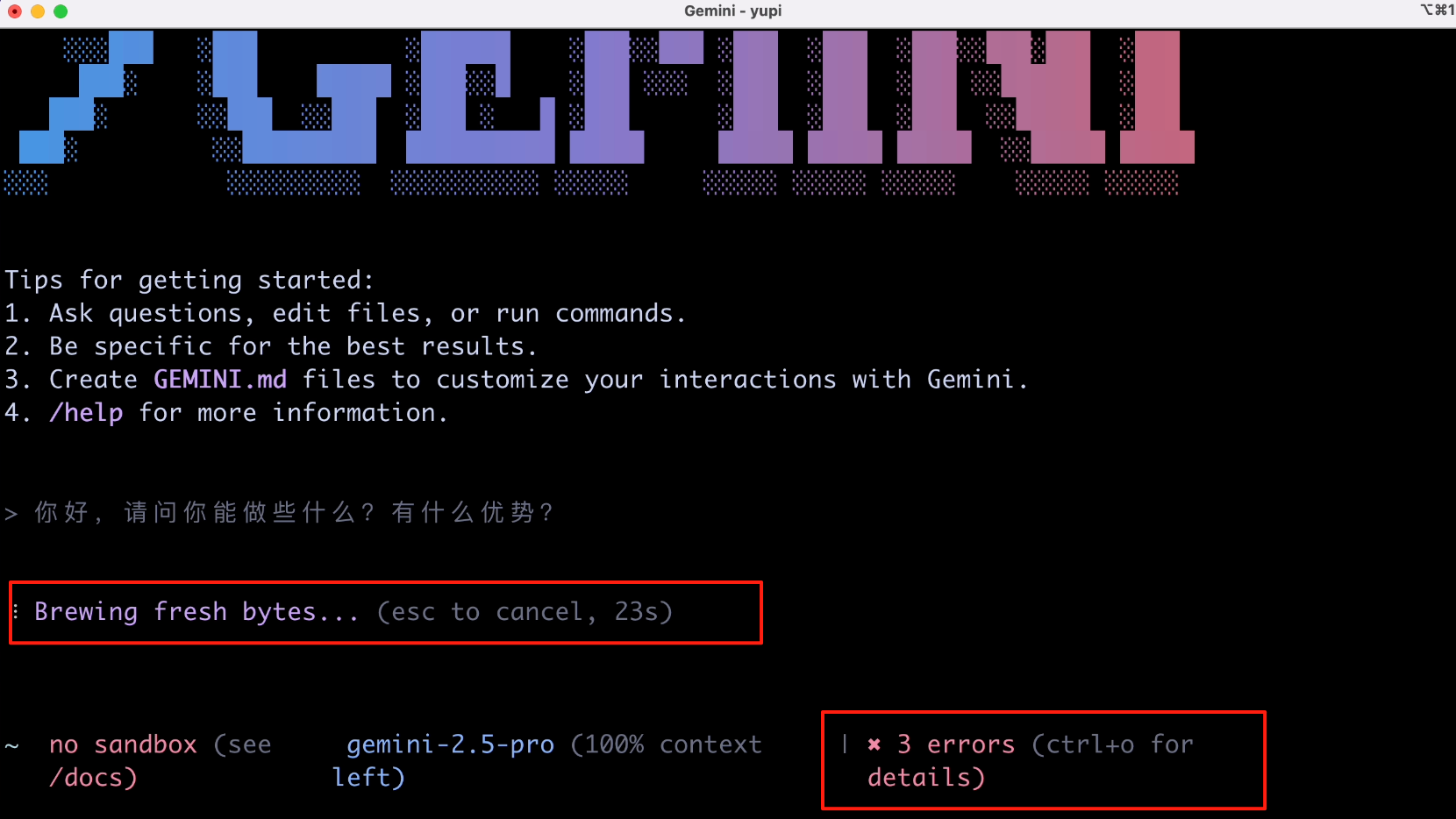
不过说实话,我确实没有发挥到 100 万 tokens 上下文的威力,测试的都是短任务,因为在这个小黑框里去跑长任务,执行过程的浏览体验确实不够好。
那先说说优点,终端操作本地文件确实更方便,而且它可以直接一行命令安装,在已有的终端中使用,不用重新下载一个终端软件,这点还是不错的。
但是问题也很明显啊,首先 AI 智能体本身的效果咱就不多说了,大家也都看到了。抛去这个之外啊,非程序员使用它的门槛还是比较高的。终端的交互体验确实是不如网页和客户端的,很难看到思考过程,界面展示和交互效果也就那样。利用 AI 来生成一下终端命令我觉得很棒(比如 Wrap AI),但如果你非要在这个框里使用 AI 来生成内容,我觉得大可不必吧,至少我应该不会这么干。
现在各家都在卷 AI,卷的是什么?易用性、成本、效果。
像我平时生活中会用豆包或者元宝,非常方便,有问题直接语音就能输入;专门编程做项目的时候会用 Cursor + Claude 的组合。那你说 Gemini CLI 的应用场景在哪里?我总不能平时有问题的时候,第一时间打开终端来问吧?用它生成代码也不好直接编辑呀。可能对擅长 Linux 服务器操作的技术大佬还有点用,但是在公司服务器上用这个还是要注意安全性。
所以我觉得中规中矩吧,没有到网上铺天盖地吹嘘的那种程度,现阶段这玩意更适合尝鲜和学习,而不是作为日常提效工具来使用。不过虽然现在体验一般,考虑到 Google 的技术实力、还有开源免费的发展模式,我相信随着版本迭代,这工具也会越来越好的。而且对我们来说多一种工具的选择,总不是坏事。
大家觉得这个工具怎么样呢?欢迎评论区留言。感兴趣的同学也可以体验一下,看看是不是和我的感受相同,还是说有一些正确的使用方式和技巧,也欢迎评论区分享。学编程和 AI 的同学,记得关注鱼皮哦,下期见~







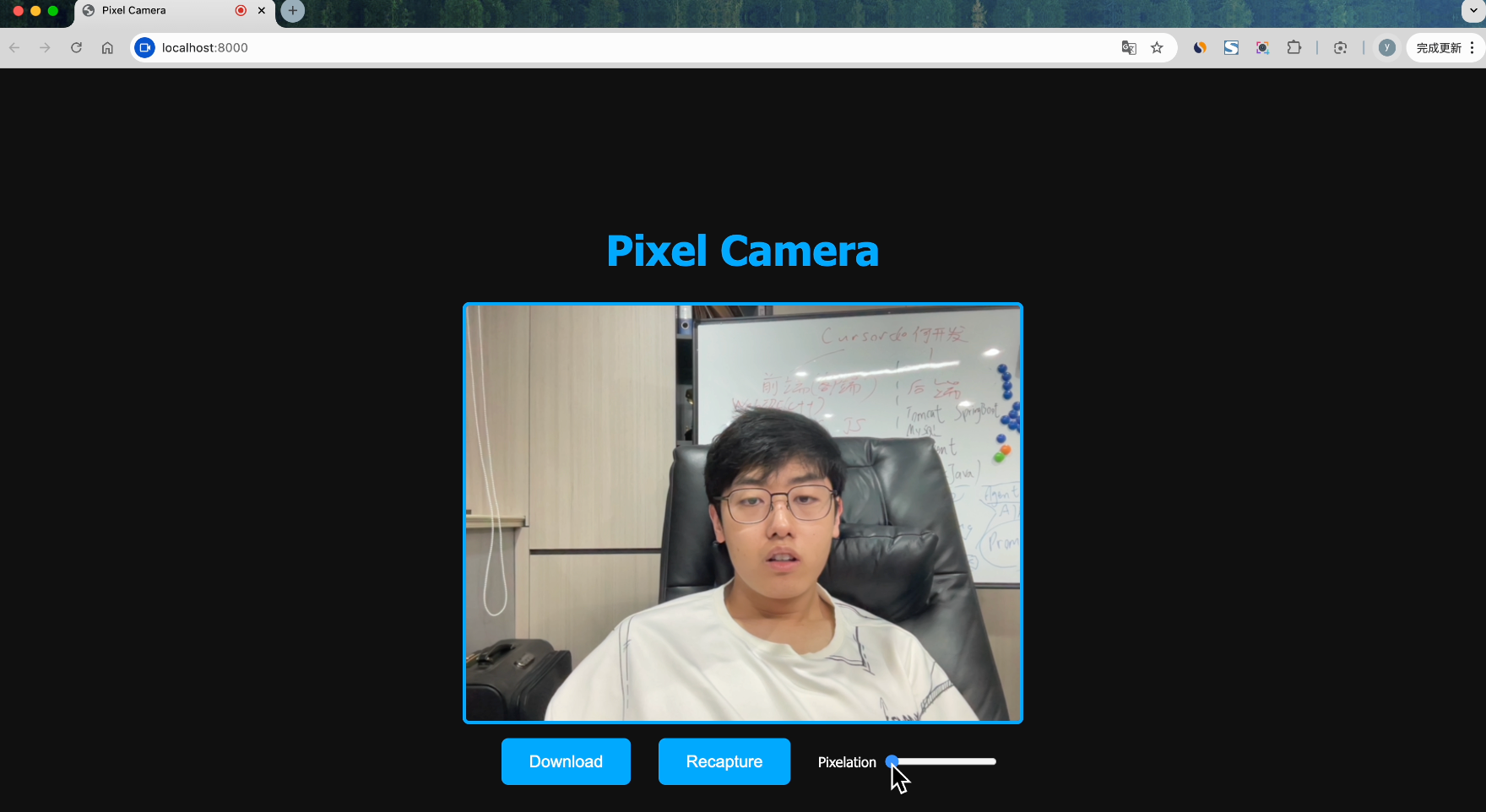
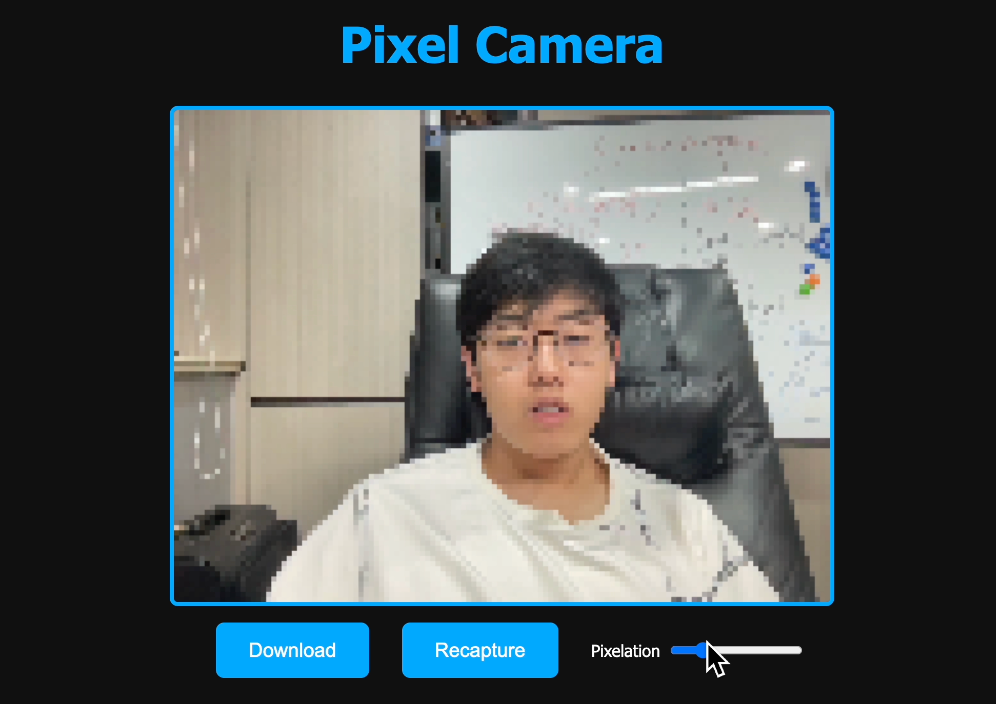


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



