前言
今天我们来探讨一个让许多技术团队纠结的问题:在分布式任务调度领域,XXL-JOB和Elastic-Job,到底哪个更好?
有些小伙伴在工作中第一次接触分布式任务调度时,可能会有这样的困惑:我们的定时任务在单机跑得好好的,为什么需要引入分布式调度框架?
当系统从单体架构演进到微服务架构,当数据量从几千条暴涨到几百万条,当业务要求从“按时执行”升级到“高效稳定”,单机任务调度就显得力不从心了。
我曾经经历过这样的架构演进:早期使用Quartz配合数据库锁,后来在千万级用户量的电商平台深度使用XXL-JOB,接着在数据处理量极大的金融项目中采用了Elastic-Job。
今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。
01 设计哲学
要理解这两个框架的差异,首先要从它们的设计哲学说起。
XXL-JOB采用中心化架构,它的核心理念是“简单清晰、开箱即用”。
设计者许雪里在框架诞生之初就明确提出:“调度中心和执行器分离,调度中心负责统一调度,执行器负责接收调度请求并执行任务”。
这种设计让XXL-JOB像一个集中指挥中心,所有调度决策都由调度中心统一做出。
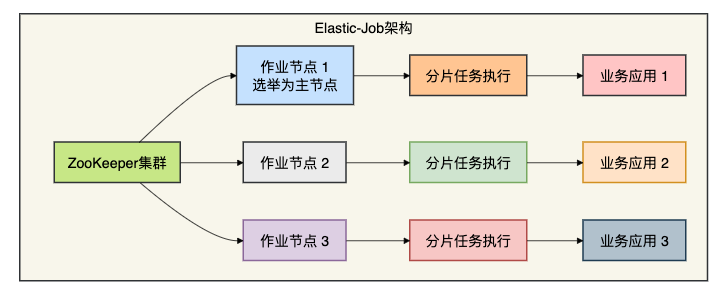
Elastic-Job则采用去中心化架构,它的设计理念是“弹性调度、分布式协调”。
框架基于ZooKeeper实现分布式协调,各个节点通过ZooKeeper选举和监听机制协同工作,没有单点中心调度器。
这就像一个自治的分布式系统,每个节点都知道自己该做什么。
这两种设计哲学的选择,直接影响了两者在不同场景下的表现。中心化架构简化了系统的复杂度,而去中心化架构则提供了更好的弹性。
02 核心架构深度剖析
XXL-JOB:简洁优雅的中心化设计
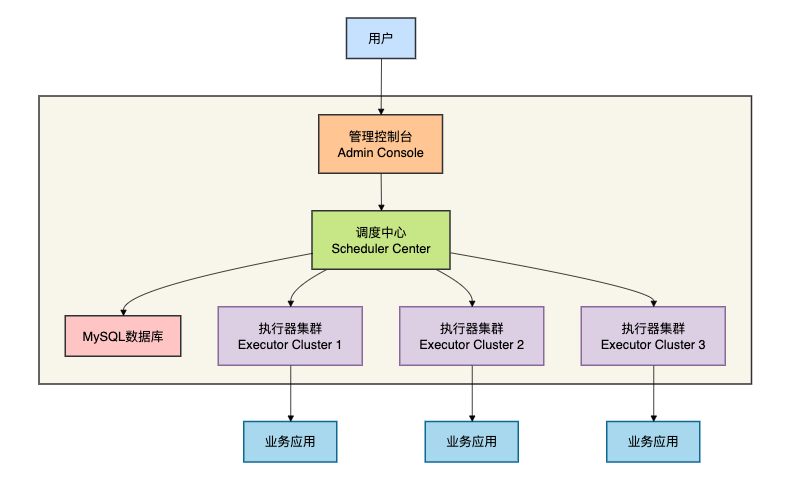
XXL-JOB的架构非常清晰,主要由三部分组成:
- 调度中心(Scheduler Center):负责管理调度信息、发出调度请求
- 执行器(Executor):负责接收调度请求、执行任务
- 管理控制台(Admin Console):提供可视化界面进行任务管理
让我们通过一个实际的例子来看看如何在Spring Boot项目中集成XXL-JOB:- // 1. 执行器配置@Configurationpublic class XxlJobConfig { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.executor.appname}") private String appName; @Bean public XxlJobSpringExecutor xxlJobExecutor() { XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appName); xxlJobSpringExecutor.setPort(9999); xxlJobSpringExecutor.setLogPath("/data/applogs/xxl-job/jobhandler/"); xxlJobSpringExecutor.setLogRetentionDays(30); return xxlJobSpringExecutor; }}// 2. 任务处理器示例@Componentpublic class SampleXxlJobHandler { @XxlJob("demoJobHandler") public ReturnT demoJobHandler(String param) throws Exception { XxlJobLogger.log("XXL-JOB, 开始执行任务"); // 模拟业务处理 for (int i = 0; i < 5; i++) { XxlJobLogger.log("执行进度: {}", i); TimeUnit.SECONDS.sleep(2); } return ReturnT.SUCCESS; } @XxlJob("shardingJobHandler") public ReturnT shardingJobHandler(String param) { // 分片参数 ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo(); int shardIndex = shardingVO.getIndex(); // 当前分片序号 int shardTotal = shardingVO.getTotal(); // 总分片数 XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal); // 根据分片参数处理数据 List dataList = queryDataByShard(shardIndex, shardTotal); for (String data : dataList) { processData(data); } return ReturnT.SUCCESS; } private List queryDataByShard(int shardIndex, int shardTotal) { // 根据分片参数查询需要处理的数据 // 例如:SELECT * FROM order_table WHERE MOD(id, #{shardTotal}) = #{shardIndex} return Arrays.asList("data1", "data2", "data3"); } private void processData(String data) { // 处理数据逻辑 XxlJobLogger.log("处理数据: {}", data); }}
Elastic-Job的架构更加分布式,它没有中心调度节点,而是通过ZooKeeper实现节点间的协调:
[code]// 1. Elastic-Job配置类@Configurationpublic class ElasticJobConfig { @Bean public CoordinatorRegistryCenter registryCenter() { CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter( new ZookeeperConfiguration("localhost:2181", "elastic-job-demo")); regCenter.init(); return regCenter; } @Bean(initMethod = "init") public SpringJobScheduler simpleJobScheduler( final SimpleJob simpleJob, final CoordinatorRegistryCenter regCenter) { return new SpringJobScheduler( simpleJob, regCenter, getLiteJobConfiguration( simpleJob.getClass(), "0/5 * * * * ?", // 每5秒执行一次 3, // 分片总数 "0=北京,1=上海,2=广州" // 分片参数 ) ); } private LiteJobConfiguration getLiteJobConfiguration( Class |


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



