最流行的7个开源目标跟踪算法
ByteTrack
ByteTrack是一种用于多对象跟踪的计算机视觉算法。它为视频中的对象分配唯一的 ID 以跟踪每个对象。大多数跟踪方法仅使用得分高的检测框,而忽略得分较低的检测框,从而遗漏一些对象并导致轨迹碎片化。ByteTrack 通过在匹配过程中使用所有检测框(从高到低)来改善这种情况。
它根据运动相似性将高分检测框与现有轨迹匹配。轨迹是跟踪对象轨迹的短片段,用于保持随时间推移的连续跟踪。通过将高分检测框与轨迹匹配,ByteTrack 即使在部分被遮挡或快速移动时也能正确识别和跟踪对象。对于低分检测,ByteTrack 会根据对象与现有轨迹的相似性从背景中识别出对象。
由于 ByteTrack 可用于跟踪视频中的多个对象,因此它可以应用于波士顿动力公司的机器人在仓库中堆放箱子等场景。这些机器人使用机器视觉来精确地抬起、移动和放置箱子。ByteTrack 可以通过精确跟踪每个箱子的位置和移动来提高其效率。
Norfair
Tryolabs 的Norfair是一个轻量级且可自定义的对象跟踪库,可与大多数检测器配合使用。用户定义用于计算跟踪对象与新检测之间的距离的函数,该函数可以像欧几里得距离的一行代码一样简单,也可以使用嵌入或 Person ReID 模型等外部数据更复杂。
它还可以轻松集成到复杂的视频处理管道中,或用于从头开始构建视频推理循环。这使得 Norfair 适用于工厂工人监控、监控、体育分析和交通监控等应用。
Norfair 提供了几个预定义的距离函数,用户可以创建自己的函数来实现不同的跟踪策略。它支持各种视频分析应用程序并支持 Python 3.8+,Python 3.7 的最新版本是 Norfair 2.2.0。
MMTracking
MMTracking是一个免费的开源工具箱,旨在分析视频。它使用PyTorch构建,是名为 OpenMMLab 的大型项目的一部分。MMTracking 的独特之处在于它将多个视频分析任务整合到一个平台中。这些任务包括对象检测、对象跟踪,甚至视频实例分割。凭借其模块化设计,您可以轻松交换这些工具以创建满足您特定需求的自定义方法。
它还可以与其他 OpenMMLab 项目(尤其是MMDetection)很好地配合使用。这意味着您只需更改一些设置即可将 MMDetection 中可用的任何对象检测器与 MMTracking 一起使用。最重要的是,MMTracking 包含预构建的模型,这些模型的准确率非常高,有些甚至比原始版本更好。
MMTracking 非常适合需要高精度和高速度的应用,例如制造业中的自动检测和自动驾驶。其模块化设计允许轻松定制,使其成为各种视频分析任务的强大工具。
DeepSORT
DeepSORT(深度简单在线实时跟踪)是 SORT 算法的改进版本。它使用深度学习特征提取器来识别各种物体,非常适合同时跟踪多个物体。DeepSORT 使用卡尔曼滤波器来预测物体运动。它非常擅长处理物体之间的遮挡和相互作用,非常适合监控和人群监控应用。
FairMOT
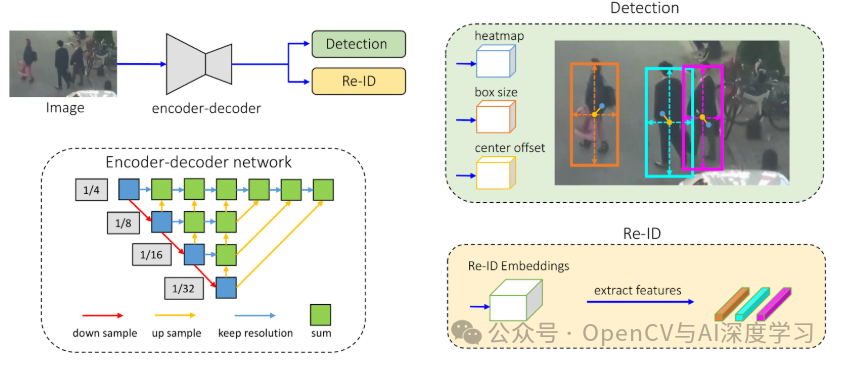
FairMOT是一种基于无锚点物体检测架构 CenterNet 的跟踪方法。与其他将检测视为主要任务、将重新识别 (re-ID) 视为次要任务的框架不同,FairMOT 将这两项任务同等对待。它具有简单的网络结构,包含两个相似的分支:一个用于检测物体,另一个用于提取重新识别特征。
FairMOT 使用ResNet-34作为主干,以实现准确度和速度的良好平衡。它使用深度层聚合 (DLA) 增强了此主干,以组合来自多个层的信息。上采样模块中的可变形卷积可动态调整以适应不同的对象尺度和姿势,这有助于解决对齐问题。基于 CenterNet 的检测分支具有三个并行头,用于估计热图、对象中心偏移和边界框大小。re-ID 分支生成特征以识别对象。
FairMOT 适用于需要平衡精度和速度的场景,例如制造车间的实时质量检测、安全监控和自动驾驶汽车导航。它能够处理遮挡和动态物体尺度,因此是这些应用的理想选择。
BoT-SORT
BoT-SORT(SORT 的技巧包)是一种跟踪多个物体的方法,它改进了 SORT(简单在线实时跟踪)等传统方法。特拉维夫大学的研究人员开发了 BoT-SORT,以便能够更准确、更可靠地跟踪物体。它结合了运动和外观信息来区分不同的物体并随着时间的推移保持它们的身份。
BoT-SORT 还包含一项称为“相机运动补偿 (CMC)”的功能,该功能考虑了相机的运动,因此即使相机不静止,物体跟踪也能保持准确。此外,BoT-SORT 使用更先进的卡尔曼滤波器,可以更精确地预测被跟踪物体的位置和大小。这些改进有助于 BoT-SORT 表现出色,即使在具有大量运动或拥挤场景的具有挑战性的情况下也是如此。它在标准数据集上的 MOTA(多物体跟踪准确度)、IDF1(身份 F1 分数)和 HOTA(高阶跟踪准确度)等关键性能指标中排名第一。
BoT-SORT 具有高精度和高稳定性的跟踪能力,是工业应用的理想选择。在大型仓库等环境中,光照条件可能会发生变化,其他物品经常会遮挡物体,但 BoT-SORT 仍能表现出色。它可用于跟踪包裹和托盘,以改善库存管理并降低物品丢失的风险。它能够监控货物从收货到发货的整个过程,有助于简化运营并提高供应链的可视性。精确的跟踪支持物流运营,实时更新每件物品的位置和状态。
StrongSORT
StrongSORT旨在改进经典的 DeepSORT 算法。它是为了解决多对象跟踪中的常见问题而开发的,例如检测准确性和对象关联。StrongSORT 使用强大的对象检测器、复杂的特征嵌入模型和多种技巧来提高跟踪性能。它还引入了两种新算法:AFLink(无外观链接)和 GSI(高斯平滑插值),它们有助于更准确地跟踪对象,而无需过度依赖外观特征。
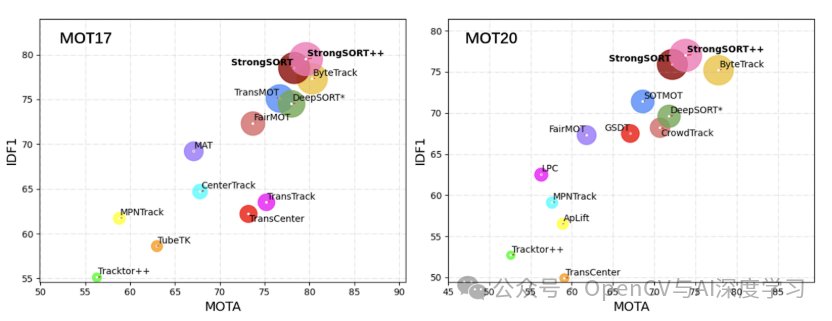
AFLink 和 GSI 都是轻量级的,易于集成到各种跟踪系统中。AFLink 仅使用时空信息即可帮助将轨迹链接在一起,使其既快速又准确。GSI 通过考虑运动信息来改进处理缺失检测的方式。这些改进使 StrongSORT 在多个公共基准测试中取得了最佳成绩,包括 MOT17、MOT20、DanceTrack 和 KITTI。
StrongSORT 的准确性和稳健性使其可用于需要非常仔细地跟踪物体的应用中。例如,假设有一个摄像头可以鸟瞰一个建筑工地,那里有许多重型车辆在不断移动。StrongSORT 可以实时监控这些车辆,帮助防止事故发生,并确保高效运营。它能够处理遮挡和多变的光照条件,即使在建筑工地动态且通常混乱的环境中也能可靠运行。
目标跟踪的挑战和限制
虽然对象跟踪技术已经取得了长足的进步,但仍然存在一些因素,导致难以获得一致的结果。使用这些对象跟踪工具时需要牢记的一些挑战和限制是:
遮挡:遮挡是指一个物体遮挡另一个物体,例如两个人擦肩而过,或者一辆车在桥下行驶。系统很难跟踪部分被遮挡的物体。
外观的变化:物体会根据其与相机的距离、角度或大小而看起来不同。
光照变化:光照变化会改变物体的外观,使检测和跟踪变得复杂。计算机视觉系统通常难以应对这些变化。
多摄像头跟踪:跨多个摄像头跟踪物体涉及一个称为 ReID 的过程,该过程涉及一组不同的算法。
可扩展性:针对许多摄像机或分散部署的扩展解决方案可能很复杂且昂贵,通常需要额外的基础设施或定制开发。
目标追踪原理
目标追踪算法的核心任务是在视频序列中持续地定位和识别同一个目标。它之所以能在上下两帧(或任意相隔的几帧)之间关联同一个目标,依赖于一整套精巧的“预测-匹配-更新”机制。整个过程可以理解为算法为每个目标维护了一个“生命力”或“身份ID”,并根据目标的运动和外观特征在时序上将其“串”起来。
1. 目标追踪算法的核心工作流程
一个典型的目标追踪算法(特别是基于检测的追踪,Tracking-by-Detection)的每一帧循环通常包括:
- 检测(Detection):在当前帧运行目标检测器(如YOLO, Faster R-CNN),得到所有潜在目标的检测框(位置、大小)和置信度。
- 预测(Prediction):对每一个已经存在的追踪目标,使用运动模型预测其在当前帧的位置。最常见的模型是卡尔曼滤波(Kalman Filter),它假设目标做匀速或匀加速运动,根据上一帧的位置和速度,预测当前帧的位置,并给出一个不确定性的范围。
- 关联(Association/Data Association):这是最关键的一步。算法需要将预测框和检测框进行匹配,决定哪个检测框对应哪个追踪目标,或者是否是新出现/消失的目标。
- 更新(Update):对于匹配成功的目标,用新的检测框信息去更新目标的状态(位置、速度)和外观特征,并修正运动模型。对于未匹配的追踪目标,可能标记为“暂失”或“消失”。对于未匹配的检测,则创建新目标。
- 管理(Management):维护所有目标的“生命周期”,处理遮挡、消失、重现等复杂情况。
2. 跨帧关联目标的关键机制
算法能实现稳定关联,主要依靠以下几大支柱:
a. 运动连续性假设(Motion Continuity)
这是最基本也是最强大的线索。相邻帧之间时间间隔极短(如0.03秒),目标物理位置不可能突变。
- 如何实现:使用卡尔曼滤波或粒子滤波。卡尔曼滤波最受欢迎,它为目标维护一个状态向量 (x, y, w, h, vx, vy, ...),预测下一帧位置。它同时考虑了观测噪声和过程噪声,给出一个高斯分布的预测区域。
- 关联方式:将检测框与预测框进行IoU(交并比)匹配或马氏距离(Mahalanobis Distance)计算。IoU高或距离近,说明是同一个目标的可能性大。
d. 轨迹管理与鲁棒性设计
- 缓冲机制:目标短暂丢失(如遮挡)时不立即删除,而是标记为“丢失态”,保留其特征库一段时间。如果后续帧中又匹配上,则“失而复得”。
- 级联匹配(DeepSORT):优先匹配最近成功更新的目标,再匹配丢失时间较长的目标,保证轨迹的连续性。
- 高分/低分检测(ByteTrack):将检测框按置信度分为高低分,先用高分框与追踪目标匹配,再用低分框与未匹配上的目标匹配,充分利用模糊检测来减少漏检和ID切换。
假设视频第T帧有目标A(ID=1,位置在(100, 100),特征向量为f1)。
- T+1帧:检测器给出两个框,Det1在(105, 102),Det2在(300, 300)。
- 预测:卡尔曼滤波预测目标A在T+1帧的位置为(103, 101)。
- 关联计算:
- 计算IoU:IoU(预测框, Det1) = 0.85(很大),IoU(预测框, Det2) = 0.01(很小)。
- 计算外观特征:提取Det1的特征f1'。余弦相似度(f1, f1') = 0.92(很高)。
- 决策:综合运动和外观,Det1极大概率就是目标A。于是将Det1分配给ID=1,并用其坐标更新卡尔曼滤波器和特征库(可能用滑动平均更新f1)。Det2则创建为新目标B,ID=2。
卡尔曼滤波原理
卡尔曼滤波为每一个目标单独维护一个状态估计器,其作用是 "预测单个目标在下一帧可能出现的位置和形状" 。这个预测结果随后被用于与检测框进行关联匹配。
更通俗的讲:卡尔曼滤波给每一个轨迹预测了下一个出现区域范围,在这个范围内出现的检测框极大可能是就是同一个目标,该轨迹就匹配范围内的检测框,不去匹配范围外的检测框,这样就能够将上下两个状态的目标关联起来。
下面详细解释其原理和在关联中的作用。
卡尔曼滤波核心原理
卡尔曼滤波是一种最优递归估计算法,它能在存在不确定性的情况下,融合预测和观测,得到对动态系统状态的最佳估计。它的强大之处在于:
- 它不只预测一个点,还预测一个概率分布。
- 它能在每个时间步动态地权衡"该信预测"还是"该信观测"。
数学模型基石
假设目标的状态向量为 x(如位置、速度),观测值为 z(如检测框坐标)。系统由两个线性方程描述:
两个核心步骤:预测与更新
卡尔曼滤波在每个时间步循环执行以下两步:
卡尔曼滤波如何"助攻"目标关联
在多目标追踪(如SORT/DeepSORT)中,卡尔曼滤波的角色如下:
总结
总的来说卡尔曼滤波的原理可以总结为三点:
卡尔曼滤波器为每个追踪目标独立维护一个状态向量 x(位置、速度等)和一个协方差矩阵 P。这个 P 矩阵正是不确定性度量,它量化了我们对当前状态估计的信心程度。通过状态向量X和协方差矩阵P可预测轨迹的下一个位置
卡尔曼滤波通过预测位置和不确定性,将关联搜索从全局缩小到局部。这是通过门控(Gating)机制实现的,通常使用马氏距离(Mahalanobis Distance)。只有落在预测不确定性椭圆内的检测框才会被考虑匹配,极大减少了计算量和错误匹配。
将预测位置和检测位置匹配成功之后,会更新每一个追踪目标的状态向量X和协方差P。目标可能由静止转为运动,或由运动转为静止,不断的更新才能更加准确的预测下一个位置。
如果预测位置和检测位置匹配不成功,则状态向量X不变,而协方差P不断增大,就会导致预测区域变大,从而出现丢失之后重新能匹配上
ByteTracker
ByteTrack 的核心思想非常直观且有效:充分利用每一个检测框,包括低分(通常是背景或被遮挡物体)的检测框,而不是简单地将其丢弃。
传统方法的局限性
在 ByteTrack 出现之前,大多数基于检测的追踪方法(如 SORT、DeepSORT)的工作流程可以概括为:
- 检测:使用目标检测器(如 YOLO、Faster R-CNN)获取当前帧中所有物体的边界框和置信度分数。
- 过滤:设置一个置信度阈值(例如 0.5)。只保留分数高于这个阈值的检测框,认为它们是“有效物体”。低于阈值的检测框被直接丢弃,通常被认为是“背景噪声”。
- 关联:将当前帧保留下来的检测框与上一帧已知的轨迹进行关联匹配(通常使用运动模型和外观特征)。
问题在于:简单地丢弃低分检测框会带来两个主要问题:
- 漏检新目标:一个新出现的、或者部分遮挡的物体,其初始检测分数可能不高,如果被丢弃,就无法产生新的轨迹。
- 轨迹中断:一个被短暂遮挡或运动模糊的已有目标,其检测分数可能会暂时下降,如果被丢弃,就会导致该目标的轨迹中断,等目标再次清晰时,系统会认为它是一个新目标,从而生成一条新的、断裂的轨迹。
ByteTrack 的创新:两次匹配
ByteTrack 解决了上述问题,其核心流程如下图所示,关键在于它对检测框进行了两次匹配:
第一步:检测
使用一个强大的检测器(论文中使用了 YOLOX)来获取当前帧的检测结果。每个检测框包含:
- 边界框 (x, y, w, h)
- 置信度分数 score
- 类别标签
第二步:分离检测框
根据一个高阈值(例如 0.6),将当前帧的所有检测框分为两类:
<ul>高分检测框:score > 高阈值。这些是外观清晰、置信度高的检测结果,很可能是真实物体。
低分检测框:低阈值 < score = 3 p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3 cv2.rectangle(image, p1, p2, color, -1, cv2.LINE_AA) cv2.putText(image, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, 2 / 3, txt_color, thickness=1, lineType=cv2.LINE_AA)def draw_trajectory(image, points, color=(0, 255, 0)): """绘制目标轨迹""" for i in range(1, len(points)): if points[i - 1] is None or points is None: continue cv2.line(image, points[i - 1], points, color, thickness=2)def iou(box: np.ndarray, boxes: np.ndarray): xy_max = np.minimum(boxes[:, 2:], box[2:]) xy_min = np.maximum(boxes[:, :2], box[:2]) inter = np.clip(xy_max - xy_min, a_min=0, a_max=np.inf) inter = inter[:, 0] * inter[:, 1] area_boxes = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1]) area_box = (box[2] - box[0]) * (box[3] - box[1]) return inter / (area_box + area_boxes - inter)while cap.isOpened(): success, frame = cap.read() if success: results = model(frame, conf=0.5) outputs = results[0].boxes.data.cpu() if outputs is not None: for output in outputs: output[4] = 0.95 # 手动设置分数,用于 ByteTrack # 更新 ByteTrack 的轨迹 tracks = byte_tracker.update(outputs, 1) for track in tracks: box_iou = iou(track[:4], outputs[:, :4]) maxindex = np.argmax(box_iou) # 获取目标的边界框和 ID box = track[:4] # Top-Left, Bottom-Right track_id = track[4] center = (int((box[0] + box[2]) / 2), int((box[1] + box[3]) / 2)) # 更新轨迹字典 if track_id not in trajectories: trajectories[track_id] = [] trajectories[track_id].append(center) # 保持轨迹长度不超过 MAX_TRAJECTORY_LENGTH if len(trajectories[track_id]) > MAX_TRAJECTORY_LENGTH: trajectories[track_id] = trajectories[track_id][-MAX_TRAJECTORY_LENGTH:] # 绘制目标的边界框和 ID if outputs[maxindex, 5] == 0: box_label(frame, outputs[maxindex], str(track[4]) + ' person', (143, 131, 226)) # 绘制轨迹 draw_trajectory(frame, trajectories[track_id], (143, 131, 226)) elif outputs[maxindex, 5] == 2: box_label(frame, outputs[maxindex], str(track[4]) + ' car', (19, 222, 24)) # 绘制轨迹 draw_trajectory(frame, trajectories[track_id], (19, 222, 24)) elif outputs[maxindex, 5] == 5: box_label(frame, outputs[maxindex], str(track[4]) + ' bus', (186, 55, 2)) # 绘制轨迹 draw_trajectory(frame, trajectories[track_id], (186, 55, 2)) elif outputs[maxindex, 5] == 7: box_label(frame, outputs[maxindex], str(track[4]) + ' truck', (167, 146, 11)) # 绘制轨迹 draw_trajectory(frame, trajectories[track_id], (167, 146, 11)) cv2.imshow("ByteTrack with Trajectories", frame) # 写入视频 videoWriter.write(frame) if cv2.waitKey(1) & 0xFF == ord("q"): break else: break# 释放资源cap.release()videoWriter.release()cv2.destroyAllWindows()[/code]执行结果:
参考:
https://zhuanlan.zhihu.com/p/1935621170272658440
说明:部分内容使用了大模型生成,整体上保持思路连贯。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |








 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



