从近期社群讨论话题来看,Vibe Coding 话题依然持续火热。作为一名 Vibe Coding 的深度用户,已经连续开发并上线了好几个产品(比如:TransDuck、OpenWrite、UnifiedTTS)。对于 Vibe Coding 之前也跟大家聊过《为什么你的 Vibe Coding 体验那么差?》,今天正好看到 Martin Fowler 博客文章《To vibe or not to vibe》,内容 DD 非常认同,这里分享给大家,看看大家是否也是这样的想法,如果不是评论区再一起聊聊,以下是正文翻译:围绕“应当在何种程度上审查 AI 生成的代码”的讨论常常显得非常二元。Vibe Coding(也就是让 AI 生成代码而不去看代码)到底是好还是坏?答案当然都不是,因为“这要看情况”。
那么,它取决于什么?
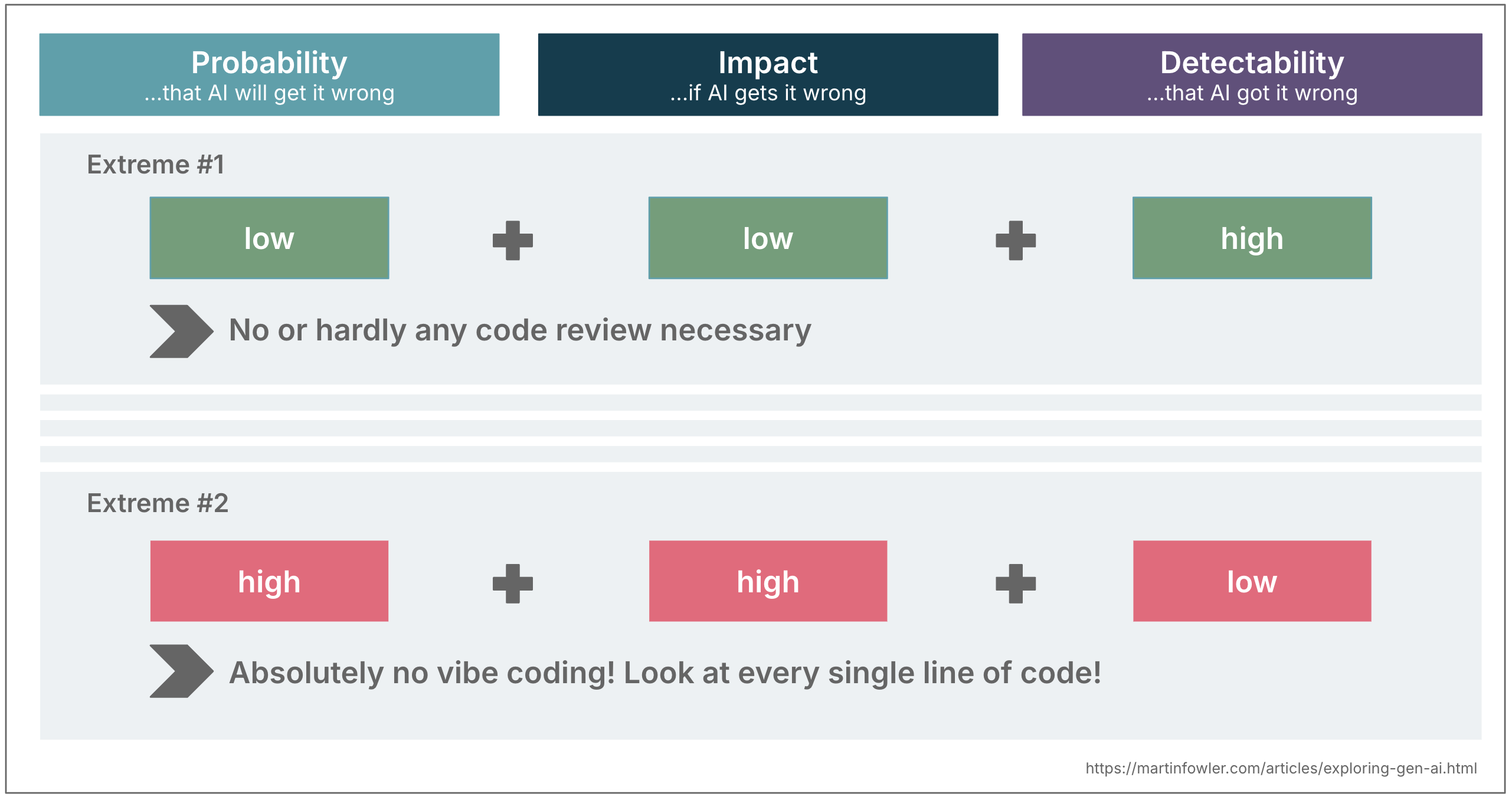
当我用 AI 写代码时,我会不断做一些微小的风险评估:是否信任 AI,信任到什么程度,以及我需要投入多少精力去验证结果。随着我使用 AI 的经验越来越多,这些评估也会变得更精准、更直觉。
风险评估通常由三个因素构成:
概率
影响
可检测性
围绕这三个维度进行思考,可以帮助我决定是否把任务交给 AI、是否需要审查生成的代码、以及审查到什么样的细粒度。这也能帮助我在想要利用 AI 的速度时,思考可以采取哪些缓解措施来降低它做错事情的风险。
1. 概率:AI 把事情做错的可能性有多大?
下面这些因素有助于判断“概率”这个维度。
了解你的工具
AI 编码助手的效果取决于所用模型、工具内部的提示编排,以及助手与代码库和开发环境的集成程度。作为开发者,我们无法掌握所有底层细节,尤其是在使用闭源工具时。因此,对工具质量的评估既来自于它宣称的功能,也来自于我们以往对它的真实使用体验。
这个用例是否“适合 AI”?
你的技术栈是否在训练数据中占比较高?你希望 AI 生成的解决方案有多复杂?AI 需要解决的问题规模有多大?
你也可以更普遍地考虑,你当前处理的是一个对“正确性”要求很高的用例,还是不是。比如,是在按设计精确还原一个界面,还是在草拟一个粗略的原型界面。
注意可用的上下文
概率不仅与模型和工具相关,也与可用的“上下文”相关。上下文包括你提供的提示,以及代理通过各种工具调用所能访问到的所有信息。
* AI 助手对你的代码库的访问是否足够,从而能做出好的决策?它是否看到了文件、结构、领域逻辑?如果没有,它生成无用内容的概率就会上升。
* 你的工具的代码搜索策略有多有效?有些工具会索引整个代码库,有些会对文件进行类似即席的 grep 搜索,有些会借助 AST(抽象语法树)构建图。了解你的工具采用什么策略会有帮助,尽管最终只有使用体验才能告诉你该策略到底效果如何。
* 你的代码库是否“对 AI 友好”,也就是是否以一种便于 AI 处理的方式进行结构化?它是否模块化,边界与接口是否清晰?还是一个很快就把上下文窗口塞满的“泥球”?
* 现有代码库是否在“树立好示范”?还是充斥着各种 hack 和反模式?如果是后者,那么如果你不明确告知什么是好的示范,AI 生成更多同类问题的概率会升高。
2. 影响:如果 AI 做错了而你没有注意到,后果是什么?



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



